データ連携「Azure Data Factory」とは?
概要と活用例をご紹介

Azure Data Factoryは、一般的にはETLと呼ばれるカテゴリの製品ですが、単なるETLに留まらない豊富で便利な機能を持っています。データ分析(アナリティクス)やDX(デジタルトランスフォーメーション)においては、収集してきたデータを加工・統合し、分析可能な形に整えて蓄積するデータ統合プラットフォームは欠かせない構成要素となっています。
本ブログでは、これから本格的なデータ活用を開始しようと考えている方々、あるいは既に開始しているが運用やコストなどの課題を抱えている方々に向けて、Azure Data Factoryの特徴、活用例、導入までの流れを解説いたします。
「社内に散在するデータを統合したい」
「DXを推進するためにデータを連携したい」
といったご要望をお持ちの方は、Azure Data Factoryで少ないデータから連携・活用まで試してみることをオススメします。ぜひ本ブログを参考にしてみてください!
目次
Azure Data Factoryとは?
Azure Data Factory (ADF) は、企業がデータを簡単に統合できるAzureベースのサービスです。コードを一切書かずにデータを統合・加工することができ、ビジネス活用できる情報に変換することが可能となります。このプロセスがこの原材料を加工して製品を生産する工場のように機能するため、”Data Factory”と名付けられました。
Azure Data Factoryでは90を超える組み込みコネクタが提供されています。データが存在する場所(クラウド、 非クラウド)、データ型やデータ ソース(SQL, NoSQL, Hadoop 等)を意識することなく、様々なデータソースを視覚的に統合し、ETLやELTプロセスを簡単に作成することが可能です。統合したデータは、Azure Synapse Analyticsなどの分析ツールに提供し、BIツールなどから活用することができます。
Azure Data Factoryを使用することで、コーディングなしで複雑なデータ統合プロセスを視覚的に構築し、段階的にETLプロセスの開発やデリバリを進めることが可能になります。また、Azure MonitorやAPなどを利用してデータ取り込み・加工の処理をを監視し、成功率や失敗率を確認することもできます。
ETL(Extract, Transform, Load)とELT(Extract, Load, Transform)は、いずれもデータを収集し、分析可能な形式に加工するためのプロセスです。ETLは、データをソースから抽出(Extract)し、必要に応じてデータを変換(Transform)してから、最終的にデータウェアハウスやデータベースなどに読み込む(Load)のに対し、ELTは、データをソースから抽出(Extract)した後、すぐにデータウェアハウスやデータベースに読み込み(Load)、必要に応じて後からデータを変換(Transform)する順序をとります。一般的にETLはデータの品質と整合性を確保するのに適している一方で、ELTはスケーラビリティと処理速度の面で利点があるとされています。
Azure Data Factoryでできること
データの取り込み
90種類を超えるコネクタが提供され、クラウドのデータウェアハウス(Amazon RedshiftやGoogle BigQuery)、オンプレミスのデータストレージ(Oracle ExadataやTeradata)、SaaSアプリケーション(Salesforce、Marketo、ServiceNowなど)からデータを収集することが可能です。
コードなしでデータ変換
ストレージに保存されているデータを自動・手動で変換することができます。
Azure Data Factoryのデータフロー機能を使えば、Apache Sparkの専門知識を持たなくても、複雑なデータ変換タスクをGUIで直感的に設計し実行することが可能です。またHDInsight Hadoop、Spark、Azure Data Lake Analytics、Azure Machine Learningなど、さまざまなAzureサービス上で複雑なデータ変換を手動でコーディングし実行することも可能です。
モニタリング機能
スケジュールされたデータ処理アクティビティやパイプラインの実行状況をリアルタイムで追跡し、成功したタスクと失敗したタスクを把握することができます。監視はAzure MonitorやAPI、PowerShell、Azure Monitor ログ、Azure portalなど、複数のツールで実行でき、必要に応じてパイプラインの最適化や調整につなげることが可能となります。
タスクの処理や関連性、アクティビティを連携させて可視化した論理的なグループのことを指します。このようなAzure Data Factoryの専門用語が他にもいくつかあります。詳しく知りたい方は、下記の資料にて解説していますのでどうぞご参照ください。
\さらに詳細を知りたい方向け/
![]() Azure Data Factory
Azure Data Factory
概要資料をダウンロードする
Azure Data Factoryの特長
オンプレミスとクラウドのデータをAzure上で一元管理できる
Azure Data Factoryは、オンプレミスのサーバーやクラウドのストレージなど、さまざまなデータソースを接続して、データを一元管理することができます。
サイロ化したデータを統合し、結合・加工など必要な処理を実施することができるため、データの一元化やデータ分析の効率的につながります。
90を超えるデータコネクタを追加費用なしで利用できる
Azure Data Factoryは90以上の組み込みコネクタを提供をしています。Amazon Redshift、Google BigQuery、HDFSなどのビッグデータソースから、Oracle ExadataやTeradataなどのエンタープライズデータウェアハウス、さらにはSalesforceやMarketoなどのSaaSアプリケーションまで、幅広いデータソースに対応しています。これらのコネクタを使用して、追加費用なしで多様なデータを統合することができます。
スモールスタートしやすい
Azure Data Factoryは従量課金制を採用しており、初期投資を必要とせずにサービスを開始することができます。小規模なデータ活用のプロジェクトをAzure Data Factoryではじめ、ニーズに合わせて拡大させる使い方が可能です。
スキルに応じて柔軟に開発できる
Azure Data Factoryは一般ユーザーから開発者向けまで、スキルに応じて柔軟に活用することができます。
例えば一般ユーザーは、ドラッグ&ドロップでデータパイプラインを作成し、開発者はカスタムコードを使用して複雑なデータ統合のワークフローを作成することが可能です。
オンプレミスのSQL Serverを簡単にAzureに移行できる
既存のSQL Server Integration Services (SSIS) のパッケージをクラウドに簡単に移行する機能を提供しており、オンプレミスのSQL ServerをAzureに移行する際の負担を軽減することができます。
Azure Data Factory 活用例
未整理のデータを統合管理
●課題 : データがバラバラに保存され、分析や活用が困難
異なるソースから収集された自社独自のデータがビジネスの洞察を得る重要な資源となります。しかしこのデータは多くの場合、オンプレミスのシステムやクラウドベースのストレージに散在し整理されていません。
●Azure Data Factoryでデータ取得と加工を自動化
ファイルサーバー、データベース、クラウドストレージなどさまざまなデータソースから未整理のデータを抽出し、分析に適した形式に変換する処理を作成します。データ抽出・変換の処理はスケジュール機能で定期的に実行し、継続的にデータの統合管理します。その後BIでの可視化やデータサイエンティストによる分析、LLMへのつなぎこみなど実施したいデータ活用につなげることが可能になります。
コードなしのデータ フローでデータ変換を高速化
●課題 : データ変換のために常にコードを書く運用だと、時間と労力がかかる
データ変換は、データ分析や活用を進めるうえで重要な役割を果たします。しかしコードを書いてデータ変換を行う方法だけでは、改善・見直しスピードが遅くなったり、属人化・メンテナンス工数の増大につながってしまいます。
●Azure Data Factoryで複雑なデータ変換を簡単・迅速に実行
Azure Data Factory のデータフローで、ドラッグ&ドロップ操作でデータパイプラインを構築し変換ロジックを実装します。変換結果は監視ツールでモニタリングし、エラーや例外処理などのメンテナンスを実施します。データ変換にかかる時間が大幅に短縮され、ビジネスインサイトの抽出が迅速に行われます。
Azure Data Factoryを活用したデータ基盤構成例
Azure Data Factoryで構成するデータ統合基盤の主なコンポーネントを図示します。ETLツールとしてのAzure Data Factoryが中心にあり、その前後にデータソースとデータ格納先が存在する構成になります。
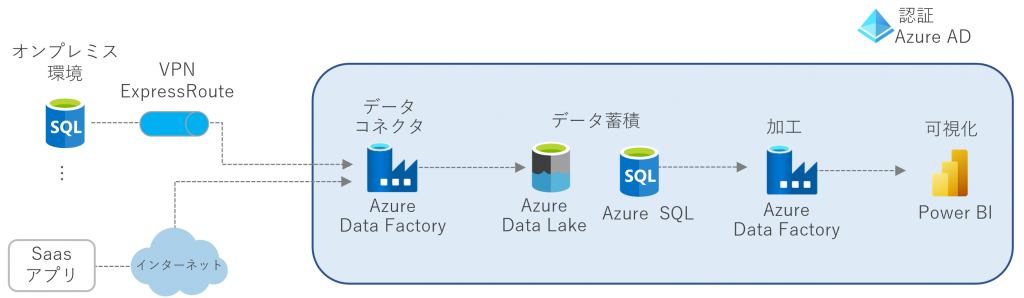
▲Azure Data Factoryで構成するデータ活用基盤の主なコンポーネント
データソース
オンプレミス上のSQL Severなどのデータベースやその他のデータベース、テキストや画像などの非構造データ、SaaSアプリケーションのデータなど多種多様なデータが利用できます。
データコネクター
Azure Data Factoryを利用することで、これらのデータを簡単に抽出・収集することができます。オンプレミスとの接続はVPN、ExpressRoute(閉域網)またSaaSとの接続はインターネット経由になります。
データの格納先
大量の生データを安価で蓄積できるAzure Data LakeもしくはAzure SQL Databaseを利用します。格納されたデータセットは、Azure Data Factoryで加工し、Power BIなどのBIツールでの分析をはじめとした各種分析に利用することができます。もちろんAIモデルの構築にも利用できます。
データのセキュリティやガバナンスを確保する各種認証にはAzure Active Directly(Azure AD)を利用します。
Azure Data Factoryのはじめ方
それでは、Azure Data Factoryの作成方法を解説します。
- Microsoft Edge、Google Chromeを起動
- Azure PoratlのAzure Data Factoryのページ(https://portal.azure.com/)にアクセス
- 「作成」を選択
- 「リソースグループ」にて、ドロップダウンからの既存のリソースグループを選択、もしくは新規作成を選択し新しいリソースグループの名前を入力
- 「リージョン」にて、Azure Data Factoryを展開するリージョンを選択
- 「名前」に、ユニークな名前を入力(Azure全体で一意の名前を入力する必要があります)
- 「バージョン」で「v2」を選択
- 「確認と作成」を選択し検証に成功後「作成」を選択、作成後「リソースに移動」を選択すて「Data Facotry」ページに移動
- 「スタジオの起動」を選択し Azure Data Factory Studio を開き、Azure Data Factoryユーザーインタフェースアプリケーションを起動
Azure Data Factoryの費用
便利なAzure Data Factoryですが、導入費用はどのぐらいかかるのでしょうか。
費用の試算に必要なのは、アクティビティとパイプラインの実行量です。アクティビティとはデータに対して実行する処理のことです。またパイプラインとは、連携して実行する一連のアクティビティの論理的なグループのことです。
まず月額コストに含まれる要素とその価格を示します。これらは初期費用なしで、使用量に基づいて課金されます。
Data Factoryパイプラインのオーケストレーションと実行
| タイプ | Azure Integration Runtime 料金 | Azure マネージド VNET 統合ランタイムの料金 | セルフホステッド統合ランタイムの料金 |
| オーケストレーション1 | $1/1,000 実行 | 利用不可/1,000 実行 | $1.50/1,000 実行 |
| データ移動アクティビティ2 | $0.25/DIU 時間 | 利用不可/DIU 時間 | $0.10/時間 |
| パイプライン アクティビティ3 | $0.005/時間 | 利用不可/時間 (最大 50 の同時パイプライン アクティビティ) |
$0.002/時間 |
| 外部パイプライン アクティビティ4 | $0.00025/時間 | 利用不可/時間 (最大 800 の同時パイプライン アクティビティ) |
$0.0001/時間 |
1. アクティビティの実行、トリガーの実行、デバッグの実行
2. Azure データセンターからデータを送信するためのネットワーク帯域幅の追加料金
3. 検索、メタデータの取得、削除、作成中のスキーマ操作 (接続のテスト、フォルダー リストとテーブル リストの参照、スキーマの取得、データのプレビュー) など
4. リンクされたサービス上で実行されるアクティビティ(Databricks、ストアド プロシージャ、HDInsight のアクティビティなど) https://docs.microsoft.com/ja-jp/azure/data-factory/transform-dataを参照
Data Flowの実行とデバッグ
| タイプ | 料金 | 1 年予約( 割引) | 3 年予約( 割引) |
| 汎用 | 仮想コア時間あたり$0.303 | 仮想コア時間あたり$0.227~25% の節約 | 仮想コア時間あたり$0.197~35% の節約 |
| メモリの最適化 | 仮想コア時間あたり$0.365 | 仮想コア時間あたり$0.274~25% の節約 | 仮想コア時間あたり$0.238~35% の節約 |
Data Factoryの操作
| タイプ | 料金 | 例 |
| 読み取り/書き込み* | $0.50/50,000 変更エンティティまたは参照エンティティ | Azure Data Factory 内でのエンティティの読み取り/書き込み* |
| 監視 | $0.25/50,000 取得実行レコード | パイプライン、アクティビティ、トリガー、デバッグの実行の監視** |
*操作には、作成、読み取り、更新、削除、エンティティには、データセット、リンクされたサービス、パイプライン、統合ランタイム、トリガーが含まれる
**監視操作には、パイプライン、アクティビティ、トリガー、デバッグの実行の取得と一覧表示が含まれる
なお非アクティブなパイプライン(定義されているが1カ月間に1度も実行されなかったパイプライン)には、月額$0.80が課金されます。
最後に構築や保守およびメンテナンスに関するご支援を弊社が承る場合の費用をお示しします。データにより価格が変動しますので、詳しくは弊社担当営業にご相談ください。
- 構築作業 1,000,000円〜
- 製品保守費用(月額) 200,000円
- データ基盤メンテナンス費用(月額) 200,000円
まとめ
Azure Data FactoryはAzure上で提供されるETLツールですが、一般的なETLと比較すると以下のアドバンテージを持っています。
- オンプレミスとクラウドの両方にあるデータを一元管理
- 90を超えるデータコネクタを追加費用なしで利用できる
- 初期投資不要の従量課金制→スモールスタートしやすい
- 一般ユーザーから開発者向けまでスキルに応じた柔軟な開発環境
- オンプレミスのSQL Serverを数回のクリックでAzureに移行可能
Azure Data Factoryを活用する際は、スモールスタートが始めるのをオススメします。まずはデータを活用する目的をしっかり考えて、その目的を達成するためにどのようなデータが必要でどのように加工すればよいかを確認します。その後Azure Data Factoryを導入し、必要なデータと加工処理を設定します。最初は少人数から始めて徐々に利用者を増やし、1つの部門で軌道に乗れば、他の部門に横展開していきます。最終的なゴールは継続的でリアルタイムな分析および判断が全社的に行われるようになることです。
Azure Data Facotry概要資料ダウンロード
機能や操作など、Azure Data Factoryをより詳しく知りたい方は是非概要資料もご活用ください。
![]() Azure Data Factory
Azure Data Factory
概要資料をダウンロードする
この記事を書いた人

-
こんにちは!日商エレクトロニクスでは、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~
- 2024年2月19日ブログMicrosoft Azure とは?基本概要、5大メリット、主要サービスを解説
- 2024年2月6日ブログ今さら聞けない「DWH」とは? ~データベースやデータマートとの比較も含めて解説!~