データレイクとは?
~DWHとの違い、メリット、活用例などをわかりやすく解説~

データを活用することがビジネスの成功に直結する現代において、データレイクはその中核をなす技術の一つとして注目を集めています。
データレイクは、異なる形式や構造を持つ大量のデータを一箇所で統合的に管理するためのストレージシステムです。
本ブログでは、データレイクに焦点を当て、その概要、データウェアハウス(DWH)などの類似製品との違い、導入メリットなどを解説します。
こんな方にオススメ
- データレイクの導入を考えている
- データレイクの概要を整理したい
- データレイクの活用例を知りたい
目次
1. データレイクとは?
データレイクとは規模や形式にかかわらず全てのデータを一元的に保存できる格納庫のことです。
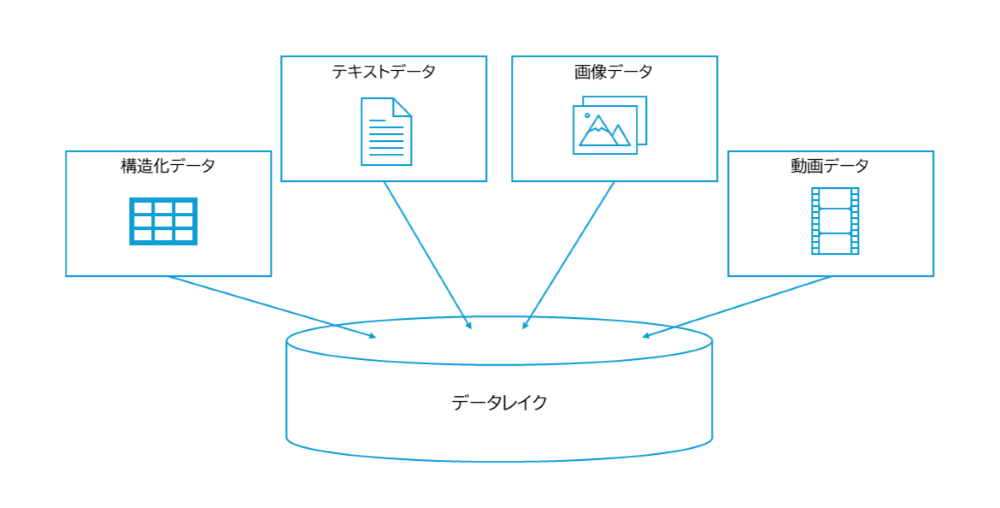
従来のデータウェアハウスが主に構造化されたデータ(例:表形式のデータ)を扱うのに対し、データレイクは構造化されていないデータ(例:テキスト、画像、動画など)や半構造化データ(例:JSON、XMLファイル)も含め、あらゆるタイプのデータを「そのまま」格納することができます。
データレイク誕生の背景には、ビッグデータの急増とデータ管理技術の進化が大きく関わっています。
①ビッグデータの時代の到来
21世紀に入り、インターネットの普及、ソーシャルメディアの登場、IoT(モノのインターネット)デバイスの増加などが起こり、企業や組織が取り扱うデータ量は爆発的に増加しました。これらのデータは従来の構造化データだけでなく、テキスト、画像、動画などの非構造化データや、センサーデータなどの半構造化データも含んでいます。この膨大なデータを効果的に管理・分析する必要性が高まりました。
②従来のデータウェアハウスの限界
ビッグデータの急増に伴い、従来のデータウェアハウスでは対応が困難になってきました。データウェアハウスは主に構造化されたデータを対象としており、非構造化データや半構造化データを扱うことが難しいです。また、データをウェアハウスに格納する前には、厳格なスキーマ定義や変換処理が必要であり、これが大量のビッグデータを迅速に処理する上でのボトルネックとなっていました。
③データ管理技術の進化
このような状況の中で、新しいデータ管理技術が求められました。それに応える形で登場したのが、「データレイク」という概念です。データレイクは、構造化されているか否かに関わらず、あらゆる形式のデータをそのまま格納し、必要に応じて分析や処理を行うことができるように設計されています。この柔軟性とスケーラビリティが、ビッグデータ時代におけるデータ管理の新たなパラダイムとして受け入れられました。
④クラウドコンピューティングの台頭
また、クラウドコンピューティング技術の進展もデータレイクの普及に貢献しています。クラウドサービス上で提供されるデータレイクサービスは、企業が自前で大規模なインフラを構築・運用する必要性を低減し、より手軽にビッグデータを活用するための基盤を提供しています。
このようにして、ビッグデータの急増とそれに対応するための技術革新が相まって、データレイクは現代のデータ管理戦略の中心的な役割を担うようになりました。
2. データレイクと類似製品との違い
データレイクには、その役割から似ている製品がいくつか存在します。今回はそのなかでも混同されがちなデータウェアハウスとデータマートと比較してみました。
①データレイクとデータウェアハウスの違い
1つ目が、データレイクと並んで重要なデータウェアハウスです。
- データレイクは構造化されていないデータも含め、あらゆる形式のデータを柔軟に管理・活用できるため、ビッグデータや多様なデータソースを扱う際に有効
- データウェアハウスは構造化されたデータの分析とレポート作成に特化しており、信頼性の高いデータを提供する
5つの観点で比較すると、下記のようになります。
| データレイク | データウェアハウス | |
|---|---|---|
| データ構造 | ローデータ | 構造化データ(RDBが多い) |
| 利用目的 | 特定の目的を持たない | データ分析に最適 |
| ユーザー | データサイエンティスト※最近ではビジネス担当者も | ビジネス担当者 |
| アクセス性 | 柔軟にアクセス可能 | 安全性と検索性が高い |
| 変更容易性 | 迅速に更新できる | 正規化されているため更新コストがかかる |
DWHは正規化(データの重複などない状態)された構造化データを格納していますので、検索や分析を高速に行うことができますが、データの加工に時間とコストがかかるためデータの収集や蓄積には不向きです。
一方データレイクはデータの形式に関係なく、生データをそのまま格納していくため、今後どのように使われるかわからないデータでもとりあえず収集し、蓄積しておくことができます。
②データレイクとデータマートの違い
データマートも、企業のデータ管理によく活用されますね。データレイクとデータマートは、主にデータの種類や管理スタイル、そして活用目的が異なります。
- データレイクは、あらゆる形式のデータを柔軟に管理・活用するための総合的なデータ保管庫であり、ビッグデータ処理や多様なデータソースを統合することができる
- データマートは、特定のビジネスニーズや業務領域にフォーカスし、構造化されたデータを最適化して整理し、特定のユーザー層が容易にアクセスできるよう設計されている
5つの観点で比較すると、下記のようになります。
| データレイク | データマート | |
|---|---|---|
| データ構造 | 構造化・非構造化・半構造化データを保管 | 主に構造化データを整理して保管 |
| 利用目的 | 多目的活用(ビッグデータ処理、機械学習、リアルタイム分析など) | 特定のビジネスニーズに合わせた分析やレポート作成 |
| ユーザ | 幅広いユーザ(データサイエンティスト、ビジネスアナリストなど) | 特定の業務部門やユーザ層にフォーカス |
| アクセス性 | 柔軟で広範なアクセス権限設定が可能 | 特定のユーザ層に適したアクセス許可設定 |
| 変更容易性 | 柔軟で変更が容易(新しいデータソースの追加や変更が容易) | 特定のビジネスニーズに合わせて整理されたため、変更が比較的容易 |
3. データレイク導入のメリット
上記の様な特徴を持つデータレイクですが、導入するとどのようなメリットがあるのか、下記にご紹介します。
① 高度な分析が可能になる
データレイクは、高度な分析の土台になります。
なぜなら、構造化されたデータはもちろん、非構造化データや半構造化データも一元的に保管でき、多種多様なデータソースを統合して管理することが可能になるからです。このようにデータを包括的に扱えることで、ビッグデータの分析や、異なる形式のデータを組み合わせた複雑な分析が行え、新たな洞察を得たり、より精度の高い機械学習モデルの構築が可能になります。
スケーラビリティに優れており、企業の成長やデータ量の増大にも耐えられます。ビジネス成長に伴うデータ量増加や将来の分析ニーズにも柔軟に対応可能です。
また、リアルタイムデータの取り込みと分析も可能な為、迅速な意思決定やビジネスプロセスの最適化が実現します。
② コストを削減できる
データレイクは、異なる形式のデータを一か所に集約できるため、データの保存や管理に関するコストを大幅に削減することができます。
従来のデータウェアハウスでは、構造化データに対応するための前処理やスキーマ定義が必要でしたが、データレイクではそのような作業が不要で、データをそのままの形で保存できます。これにより、データの取り込みから分析までのプロセスが簡素化され、時間とコストの節約につながります。
また、クラウドベースのデータレイクサービスを利用することで、インフラのコストも削減できます。
4. データレイク導入時の課題
データレイク導入時には、留意すべき点もいくつかあります。
① データスワンプ(データの沼)に陥いらないようにする

データスワンプとは、データが大量に蓄積される一方で、整理や管理が適切に行われず、価値のある情報を見つけることが困難な状態を指します。
データスワンプに陥ると、以下のような問題が生じてしまいます。
- データの重複と冗長性
同じデータが複数の場所に保存されることで、データの重複や冗長性が増加し、データの一貫性が損なわれる可能性があります。 - データの品質低下
データが整理されずに保管されると、データ品質が低下し、誤った情報や不正確なデータが増加する可能性があります。 - 発見性の低下
上記の状態だと、必要な情報を見つけることが困難になります。データを取得する際の手間や時間が増加し、効率的なデータ活用が阻害されます。 - 意思決定の遅延
データスワンプに陥ると、必要な情報を見つけるだけで多くの時間を費やすため、意思決定プロセスに遅延が生じる可能性があります。
これを防止するには、データカタログなどメタデータを管理できる仕組みを入れ、データガバナンス体制を確立する必要があります。
② セキュリティ強化を行う

データレイクには全社規模の大量のデータが格納されることが多いです。
そのため、データのアクセス権をきちんと管理し、必要なユーザに必要な権限が付与されるようにすることが非常に重要です。不適切なアクセス権の管理は、データの漏洩や誤用を招き、企業のセキュリティや信頼性に深刻な影響を及ぼす可能性があるからです。
これを防止するには、
- 最小権限の原則
- ロールベースのアクセス制御
- 監査ログの活用
など、必要なセキュリティ設定を行う必要があります。
5. データレイクの活用例
① 顧客とのやり取りの改善に活用

データレイクを利用することで、顧客とのやり取りの改善が期待されます。
具体的には、以下の様な改善が可能になります。
- 顧客行動の理解
顧客が生成する様々なタイプのデータ(ウェブサイトの訪問記録、購入履歴、ソーシャルメディアでの活動など)を集約し、分析することで、顧客の行動パターンやニーズをより深く理解することができます。 - パーソナライズされたコミュニケーションの実現
顧客ごとのデータを分析することで、一人ひとりの興味やニーズに合わせたパーソナライズされたメッセージやオファーを提供できます。これにより、顧客満足度の向上につながります。 - 顧客体験の最適化
顧客からのフィードバックやその他のインタラクションデータを分析することで、顧客体験を継続的に改善できます。例えば、ウェブサイトのナビゲーション改善や、より効果的なカスタマーサポートの提供が可能になります。 - リアルタイム対応の実現
データレイクを活用してリアルタイムデータを処理するシステムを構築することで、顧客の現在の行動に基づいた即時の対応が可能になります。例えば、オンラインショッピング中の顧客に対し、リアルタイムでおすすめ商品を提示することができます。 - 顧客離脱の予防
顧客の行動データやトランザクションデータから流失の兆候を早期に検知し、特定の顧客に対してリテンション(保持)戦略を展開することが可能です。例えば、特別なオファーや個別のコミュニケーションを通じて、顧客の離脱を防ぎます。
② 研究開発への活用

データレイクは研究開発プロセスにおける選択肢を増やし、組織全体のイノベーションを促進する強力なツールとなりえます。
具体的には、以下のような方法で実現できます。
- 多様なデータソースの統合
データレイクは、構造化データだけでなく、非構造化データや半構造化データも格納できます。これにより、社内外のさまざまなデータソースから膨大な量のデータを集約し、これまでにない視点からの分析が可能になります。 - 高度なデータ分析と機械学習の活用
データレイク上で高度なデータ分析や機械学習アルゴリズムを利用することで、新たな発見や予測が可能になります。これは、未知の市場ニーズの特定や新製品・新サービスの開発に直接つながります。 - 迅速なプロトタイピングとテスト
大量のデータを活用してシミュレーションや仮説検証を行うことで、研究開発プロセスを加速します。これにより、失敗リスクを低減しながらも、より多くのアイデアを迅速にテストし、選択肢を増やすことができます。 - コラボレーションの促進
データレイクは、異なる部門や組織間でのデータ共有とコラボレーションを容易にします。多様な専門知識を持つチームが共同でデータを分析し、新しい解決策を生み出すことで、イノベーションの選択肢が広がります。
その他、下記の様な項目でデータレイクを活用することができます。
- 予測分析とトレンド分析:過去のデータを基に未来のトレンドや需要を予測し、ビジネス戦略や在庫管理、製品開発などを最適化します。
- サプライチェーンの最適化: サプライチェーンに関わるデータ(在庫、物流、供給者パフォーマンスなど)を分析し、効率性の向上やコスト削減を図ります。
- 顧客セグメンテーション:顧客データを分析して顧客群を細分化し、ターゲットマーケティングやカスタマイズされた製品・サービスの提供に活用します。
- スマートシティの実現:交通流動データ、公共施設の利用データなどを分析し、都市計画や公共サービスの改善に役立てます。
- 製品品質の向上:製造プロセス中に生じる大量のデータを分析して品質管理を行い、製品の不良率を低下させます。
6. データレイク導入時に必要な周辺の技術
データレイクは、導入するだけで上記の様な活用ができるわけではありません。ビジネス価値を最大化するためには、他の技術やツールを組み合わせることが不可欠です。
多くの企業は、以下の4つの技術を組み合わせることにより、データ活用基盤を作成しています。
① データの移動
データを異なるソースからデータレイクに移動するためのETL(抽出、変換、ロード)ツールが必要です。これにより、データの収集と統合を効率化し、データの一元化を実現します。
② データのセキュアな保存とカタログ化
前述の通り、データレイクはデータスワンプに陥りやすいという問題点があります。それを防ぐために、データをセキュアに保存し、アクセス権限の管理やデータ暗号化を行うセキュリティ技術が必要です。また、データカタログツールを使用して、データのメタデータ管理や検索性を向上させる必要があります。
③ 分析
データは、溜めるだけでは意味がありません。それを可視化し、優れた分析を実現するために分析ツールやビジネスインテリジェンス(BI)ツールが必要です。これにより、データから洞察を得て意思決定をサポートします。
④ 機械学習
データからパターンや予測モデルを構築するために機械学習アルゴリズムやモデル開発フレームワークが必要です。機械学習を活用することで、データから価値ある情報を抽出し、新たな洞察を得ることが可能となります。
7. 代表的なデータレイクサービス
最後に、代表的なデータレイクサービスをご紹介します。データレイクはデータ容量が多くなりがちなので、より安価で柔軟性のあるクラウドサービスが良く選択されます。
AWS
AWSでは、Amazon S3を用いて実現します。データの処理や分析を行うためには別途データ処理サービス(例: Amazon EMR)を使用することで実現できます。
Amazon S3は汎用的なオブジェクトストレージサービスとして広く利用されており、柔軟性や拡張性に優れたストレージソリューションとしての特徴があります。
Google Cloud Platform(GCP)
GCPにおいては、AWSと同じように、ストレージサービスとデータ処理サービスを組み合わせて実現します。
具体的には、Google Cloud Storage (GCS)とCloud Dataprocを組み合わせる、等です、
Azure
Microsoft Azureからは、データレイクのサービスであるAzure Data Lakeが提供されています。
Azure Data Lakeには大きく3つの機能が備わっています。1つはデータを格納する領域の「Azure Data Lake Store」、2つ目は格納したデータを分析するための「Azure Data Lake Analytics」、3つ目はデータを管理するための「Azure HDInsight」です。
これらの機能によりさまざまな種類のデータを格納し、複数のプラットフォームと言語で処理/分析を簡単に実行できるようになります。複雑性は排除されているのでデータを保存/分析する方法に悩むことなく、大規模なデータセットの処理やペタバイト規模のファイルと数十億個のオブジェクトを保管/分析することが可能です。
\各機能について知りたい方は資料もご参照ください/
![]() Azure Data Lakeの
Azure Data Lakeの
概要資料をダウンロードする
以上、いかがでしたでしょうか?Azure Data Lakeにご興味をお持ちいただけましたら、ぜひ下記のフォームよりお問い合わせくださいね。
どうぞよろしくお願いいたします。
この記事を書いた人

-
こんにちは!日商エレクトロニクスでは、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~
- 2024年2月19日ブログMicrosoft Azure とは?基本概要、5大メリット、主要サービスを解説
- 2024年2月6日ブログ今さら聞けない「DWH」とは? ~データベースやデータマートとの比較も含めて解説!~