1. はじめに
本稿ではアプリケーションをAzureへの移行担当者をターゲットに、実際にデプロイしたAzure SQLデータベースへデータを挿入し、スケールアップによる相対的なパフォーマンスの向上を確認しました。また、Azure SQLデータベースの可用性の考え方とデータベースの運用に欠かせないバックアップ機能についても調査します。
1-1. Azure SQLデータベースとは
Azure SQLデータベースは、Microsoft SQLデータベースを提供するAzureのPaaSサービスです。利用者がWindowsサーバーへMicrosoft SQLのソフトウェアをインストールし設定する必要はなく、必要に応じてすぐに使い始められるのが特徴です。Microsfot SQLサーバーなので、Microsoft SQL Management Studioといった使い慣れた既存のデータベース管理ツールからの接続も可能です。(一部対応していないものも存在します。)
2. Azure SQLデータベースの作成と接続
2-1. Azure SQLデータベースの作成
Azure PortalからSQLデータベースを選び、追加ボタンをクリックすると新規データベースをデプロイできます。
作成ボタンをクリックしてから数分後にはデータベースに接続できる状態となりました。
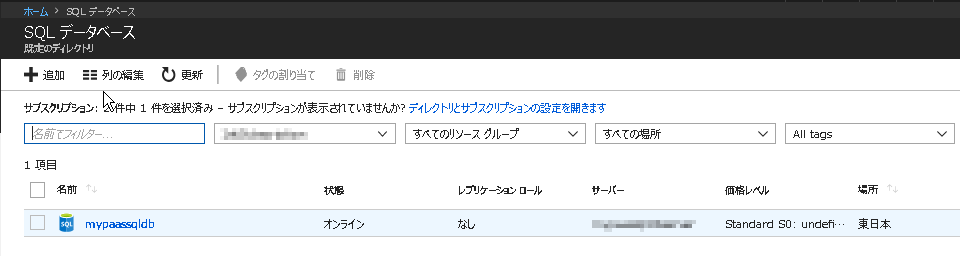
なお、PaaSのAzure SQLデータベースをデプロイするにあたり、データベースを擁する”サーバー”をあわせて作成する必要があります。利用者は、アプリケーションからAzure SQLのサーバーの提供するFQDNへ接続しデータベースにアクセスします。Azure SQLを使い始めるにあたり、取り急ぎはサービス単位でAzure SQLのサーバーを作成しておけば問題ないでしょう。

個別のデータベースではなく、SQLサーバーの単位で共有する設定のうち代表的なものを表 2―1 Azure SQLサーバーで管理を行う単位(一部抜粋)にまとめました。設定は個々のデータベースではなくAzure SQLサーバーの単位となります。
| 管理対象 | 説明 |
| ログインID | Azuer SQLデータベースへアクセスアクセスを許可するSQLの認証情報や、Azure ADユーザー |
| DTUクォータ | サーバー内の各データベースのDTUの上限値 |
| ファイアウォール | サーバーに接続するクライアントのIPアドレス制限 |
| Elastic Pool | DTUのまとめ買いのようなイメージ。データベースごとに個別にDTUを確保するのではなく、サーバー内のデータベース内でDTUを共有できる柔軟性がある。 |
| ログ | 監査ログ、診断ログなど |
図表 2-1 Azure SQLサーバーで管理を行う単位(一部抜粋)
2-1-1. データベース接続文字列
作成したデータベースの設定メニューから、接続文字列を選択すると各環境に応じたデータベースへの接続子を確認できます。今回は接続にMicrosoftから提供されるmssql-jdbcパッケージを利用するため、環境にあわせJDBCの接続文字列をコピーして利用します。なお、パスワードはマスクされているのでそのままコピーしても接続できません。データベース作成時に決めたパスワードに置き換えて接続する必要があります。
2-2. Azure SQLデータベースへの接続
デプロイの完了したAzure SQLデータベースに接続すべく、さっそくmssql-jdbcパッケージをインポートしAzure SQLデータベースへログインを試みたところ、以下例外が発生しました。
com.microsoft.sqlserver.jdbc.SQLServerException: Cannot open server ‘xxxxxxxxx’ requested by the login. Client with IP address ‘xxx.xxx.xxx.xxx’ is not allowed to access the server. To enable access, use the Windows Azure Management Portal or run sp_set_firewall_rule on the master database to create a firewall rule for this IP address or address range. It may take up to five minutes for this change to take effect. ClientConnectionId:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx
エラーメッセージの内容より、クライアントIPアドレスにより接続が拒否されていることからデフォルトではインターネットからのアクセスは許可されない設定となっているようです。 そこで、Azure Portalに戻って確認してみると、”ファイアウォールと仮想ネットワーク”という設定項目が有効となっていました。 もしAzure Portalを開いているWebブラウザと同じ端末からAuzre SQLデータベースへ接続しようとしている場合は、画面上に表示されている接続元クライアントIPアドレスをそのまま許可すればよいし、別のアプリケーションサーバーから接続しようとしている場合はそのアプリサーバーのグローバルIPアドレスを登録してやればデータベースへ接続できるようになるはずです。
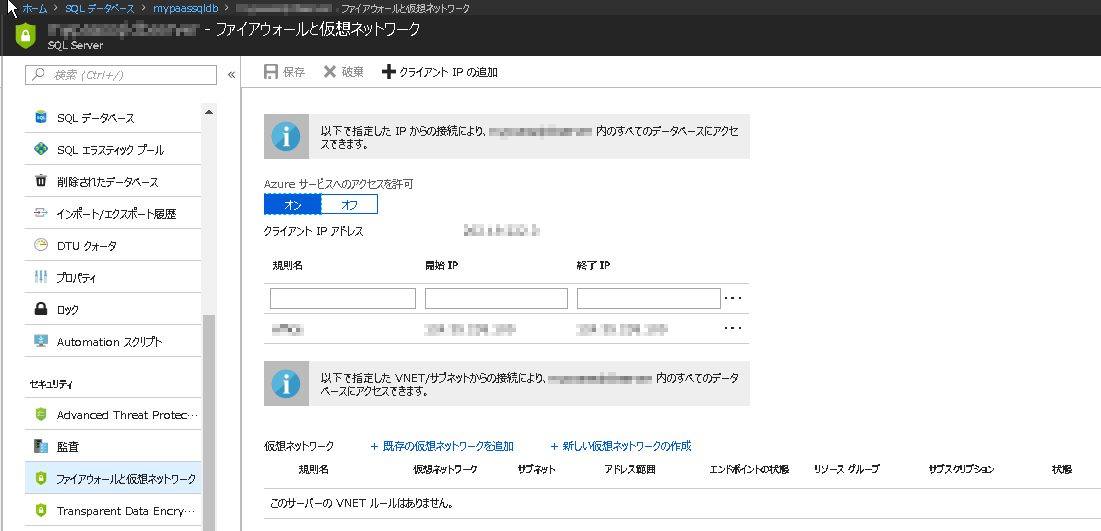
図表 2-2 Azure SQLのファイアウォール設定
2-3. テーブルの作成
テーブルのカラム名として、Azure SQLデータベースで予約語となっている”plan”をうっかり含めてしまったことが原因で、構文エラーに悩まされました。全角の文字やAzure SQLで利用可能でないデータ型名や綴りの誤りがないか一字一句確認しましたが、予約語をカラム名にしようとするとエラーとなるという常識的なミスでした。
ここでは、プランIDを格納するカラム名を、予約語である”plan”から”planId”に変更することでエラーを回避しました。
外部リンク: Reserved Keywords (Transact-SQL)
2-4. データの挿入
今回は各拠点の擬似IoTハブが擬似ローカルデバイスからのデータをとりまとめ、定期的にPaaSのAzure SQLデータベースにデータを登録する構成を想定し、1,000~3,000件ずつのバッチに分けてAzure SQLデータベースへ実際に格納するサンプルアプリケーションの実装としました。
while(rows.hasNext()){ ⇒拠点内の各デバイスからのデータをAzure SQLへプッシュ。(一度に1000件~3000件)
row=rows.next();
pstmt.setStting(1,row.getString(“devId”));
pstmt.setStting(1,row.getString(“planId”));
pstmt.setString(2,row.getString(“dateTime”));
pstmt.setFloat(3,row.getFloat(“highTemp”));
pstmt.setFloat(4,row.getFloat(“lowTemp”));
pstmt.setFloat(5,row.getFloat(“highHumidity”));
pstmt.setFloat(6,row.getFloat(“lowHumidity”));
pstmt.addBatch();
}
result=pstmt.executeBatch();
Log.v (result.length+”rows have been inserted.”);
図表 2-3 Azure SQLデータベースにまとまった単位でデータを挿入するサンプルコードの一部
3. Azure SQLデータベースのパフォーマンス
3-1. DTU(データベース トランザクション ユニット)
Azure SQLデータベースをサイジングするにあたってはDTU(データベース トランザクション ユニット)という概念が登場します。DTUとはMicrosoft社が定義する相対的なデータベースのパフォーマンスを表す指標で、DTUが2倍になると、データベースの性能も2倍になるらしいです。今回選んだプランはスタンダードの10DTUです。
3-2. テストアプリケーションの実行
ためしにサンプルコードを実行してみたところ、データベースリソース使用率はほぼ100%張り付きとなりました。
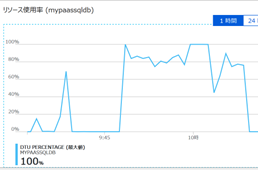
図表 3-1 サンプルアプリケーション実行時のデータベースリソース使用率
リソース使用率が100%ということは、アプリケーションのボトルネックがデータベースにあるということです。より高いDTUのプランへAzure SQLをスケールアップしてやることでアプリケーションの実行時間に占めるデータベースのクエリの実行待ち時間を少なくしてやることがボトルネック改善に向けたファーストステップとなることは誰でも想像できるでしょう。
3-3. DTUのスケールアップ
AzureではクリックひとつでDTUを変更できます。今回はStandardな10DTUのデータベースを100DTUにスケールアップしました。実際の操作は設定画面からスケールアップ先のDTUを選んで決定ボタンをクリックするだけの簡単操作です。

図表 3-2 DTUの変更画面
3-4. DTUスケールアップの効果
アプリケーションを実行しながらDTUのスケールアップを行ったところ、設定変更完了後にAzure SQLのデータベース使用率が40%以下に減少しました。
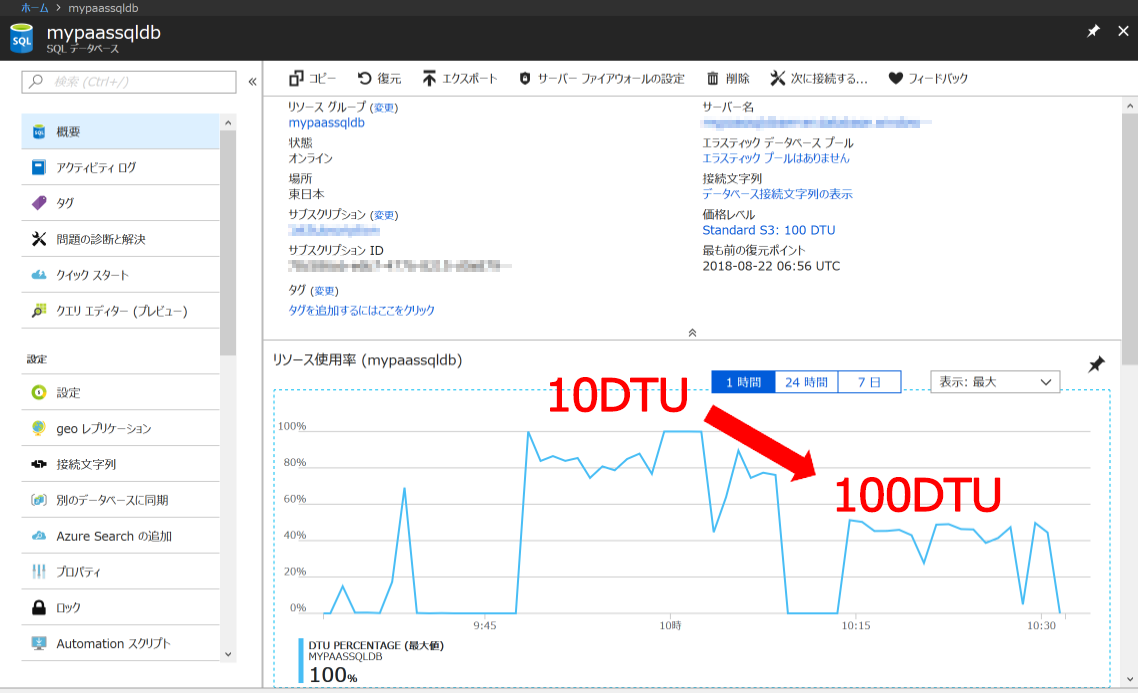
図表 3-3 Azure SQLデータベース DTUの変更結果
3-5. アプリケーション観点でのパフォーマンス
アプリケーションがはじめの22,061行のデータを擬似IoTハブからAzure SQLデータベースに挿入する際に実行されるバッチに要する時間を測定しました。その結果100DTUのときは、10DTUと比較しおよそ40%所要時間が短縮されました。 DTUを増やすことで、実際のアプリケーションのパフォーマンスが向上したことがわかります。
一方で、DTUの増強後リソース使用率は40%程度にとどまっていることから、現時点ではそこまでのDTUが必要ないという考えのもと、プランを50DTUにとどめアプリケーションパフォーマンスとコストのバランスをとるという中間の選択もありでしょう。
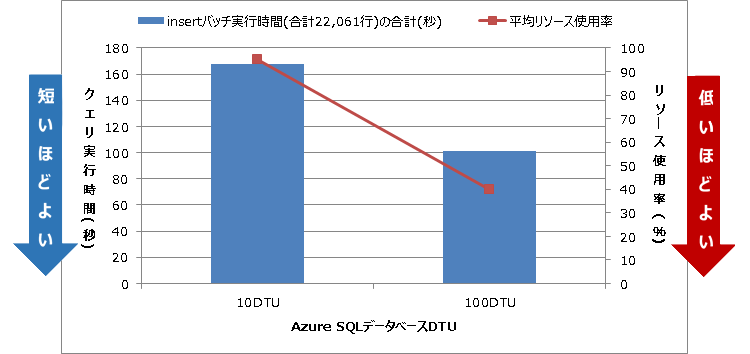
図表 3-4 DTU増強によるクエリ総実行時間とリソース使用率の推移
Azure SQLデータベースのDTUはいつでも変更できるので、Webサイトやアプリケーションの繁忙期の前にDTUを高くしておけば機会損失を防ぎ、収益率最大化に貢献できそうです。また、むこう数年間維持しておかなければならないほとんどアクセスのないサービスには最小のDTUを割り当てておけば維持運用コストの削減にもに貢献できるはずです。
はじめから高価なサーバーを用意しておかなくても、必要に応じてプランを変更できるというのはPaaSのメリットです。
4. 可用性
Azure SQLデータベースはデプロイされた時点で高い可用性の備わったSQLデータベースとして提供されます。オンプレミスでWindowsサーバー上にMicrosoft SQLデータベースを構成するときのように、SQLサーバーを2台準備しクラスタを組むといった手間が不要なため、アプリケーションの開発と移行に集中したい担当者にとっては便利です。2018年8月現在、いずれのプランにおいても99.99%のSLAを実現していますが、Premiumプランはさらに、メンテナンス中でもパフォーマンス影響が最小となる仕組みとなっているといいます。
| プラン | 可用性(SLA) | 備考 |
| Basic | 99.99% | |
| Standard | 99.99% | |
| Premium | 99.99% | メンテナンス中でもパフォーマンス影響は最小 |
図表 4-1 Azure SQLデータベースの可用性
外部リンク: 高可用性と Microsoft Azure SQL Database
4-1. バックアップ
4-1-1. 短期バックアップ(ポイントインタイム)
Azure SQLデータベースではバックアップが地理的に離れた別のリージョンへ標準で取得される仕様です。いつでも別のSQLサーバーへバックアップデータをリストアすることが可能です。
- バックアップ保持期間
Azureのサイトによると、バックアップの頻度は以下の通りです。
| プラン | リテンション期間 |
| Basic | 7 |
| Standard | 35 |
| Premium | 35 |
図表 4-2 Azure SQLのポイントインタイムバックアップ保持期間
- バックアップ実行間隔
Azure SQLデータベースのバックアップでは、1週間ごとにフルバックアップが実行され、12時間ごとに差分バックアップが実行されます。また、トランザクションログに関しては5-10分間隔で実行されるそうです。
ためしに、16:05の時点で復元ボタンをクリックしてみたところ、UTC時間の06:56(日本時間の15:56)のポイントを復元可能なことから、きちんと仕様どおりにバックアップが取得され、実際に復元可能な状態で提供されていることがわかります。
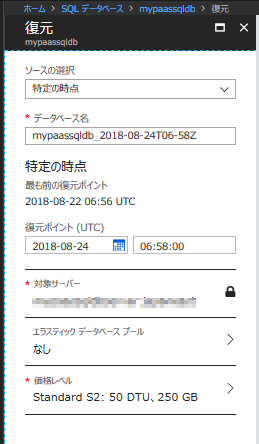
図表 4-3 Azure SQLデータベース復元メニュー
とりあえずバックアップが取得されているという点で、Azure SQLデータベースの導入のハードルが下がるのはうれしい仕様です。
4-1-2. 長期バックアップ
短期バックアップは保持期間を過ぎたものから順に消えて行ってしまいますが、Azure SQLデータベースは最大10年間にわたって週次/月次バックアップ保存にも対応しています。こちらは別途設定が必要です。
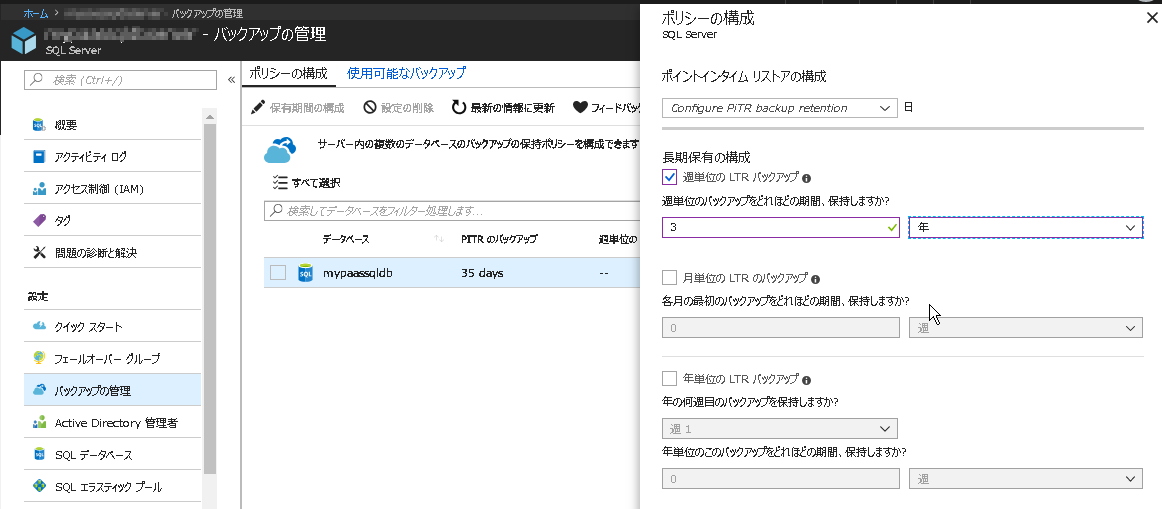
図表 4-4 週次のバックアップを3年間保存する設定例
4-2. BCP(事業継続)対策
Azure SQLデータベースも、異なるリージョンにまたがり最大4つの読み取り可能なレプリカを構成可能です。大規模災害による業務停止のリスクに備え、地理的に離れた場所へデータベースをレプリケーションしいつでも切り替え可能としている企業はいまでは珍しくないでしょう。 通常時はセカンダリデータベースとして、読み取り専用でプライマリデータベースの負荷をオフロードするために活用し、災害発生時は、稼働中のリージョンのデータベースを書き込み可能に切り替えられるようアプリケーションを設計することで、ポイントインタイムのリカバリと比較し、事業再開までのRTO(復旧目標時間)を短縮するといったような構成もAzureポータルより可能です。こちらも詳しくはAzure SQLデータベースのWebサイトをチェックしてください。
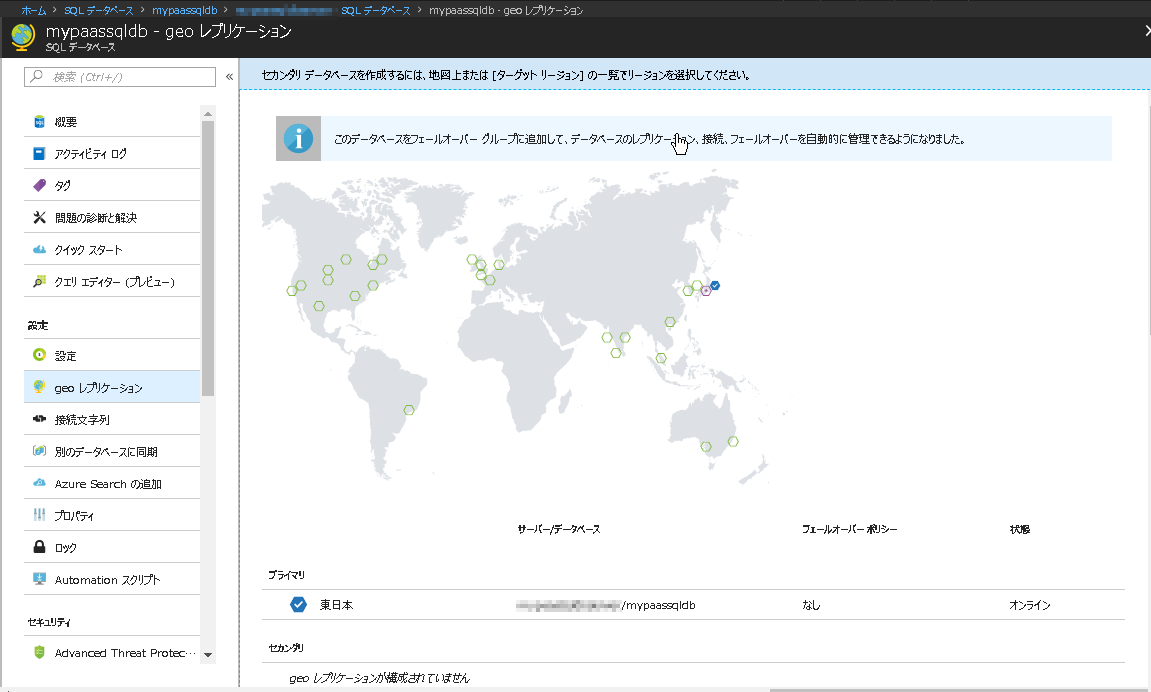
図 4-5 geoレプリケーション設定画面
5. まとめ
Azure SQLデータベースはSQLデータベースを自分でデプロイする場合と比較し、性能のサイジング、デプロイの手間、高可用性の実現、バックアップ取得の観点で導入のハードルがと低いことがわかりました。必要であればDRの構成もAzureポータル上で実現できます。
アプリケーションサーバーもAzure SQLデータベースとの同一のAuzreリージョンへ展開する計画であれば、ネットワーク的な距離も近くなるため良好なレスポンスが期待できるでしょう。
AzureにSQLデータベースの配置を計画しているアプリケーション担当者は、手始めにAzure SQLデータベースの利用を検討してみてはいかがでしょうか。
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

-
こんにちは!日商エレクトロニクスでは、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~
- 2024年2月19日ブログMicrosoft Azure とは?基本概要、5大メリット、主要サービスを解説
- 2024年2月6日ブログ今さら聞けない「DWH」とは? ~データベースやデータマートとの比較も含めて解説!~