目次
1. はじめに
皆さんこんにちは。
今回はAzure Databricks Delta Live Tablesについて説明していきます。
この連載では、Azure DatabricksのDelta Live Tablesの基本から実行手順について説明していきます。
第1回:Delta Live Tablesの基本を知ろう(今回)
第2回:Delta Live Tablesのパイプラインを実装してみよう
第3回:Delta Live Tablesのデータの品質管理とは?
2.Delta Live Tablesとは?
Delta Live Tablesは、Azure Databricksでデータパイプラインを簡単に作成・管理・実行できる機能です。
データセット(テーブルやビュー)を定義し、それらの間の依存関係を自動的に推論します。
また、現在の状態と目的の状態を比較し、効率的な処理方法でデータセットを作成・更新することができます。
任意のデータソースからDelta Live Tablesにデータをロードできます。
【メリット】
・SQLまたはPythonでエンドツーエンドのデータパイプラインを容易に定義できる
・ストリーミングに対応し、新しいデータだけを処理して、常に最新のデータを提供する
・データパイプラインの実行状況やパフォーマンスを可視化し、監視や回復を容易にする
・データ品質を向上させるための機能が提供される
⇒ 例えば、データ品質ルールを定義してデータの正確性や完全性を検証したり、
ダッシュボードでデータ品質の状況を監視したり、
問題が発生した場合にアラートを受け取ったりできます。
3.パイプラインとは?
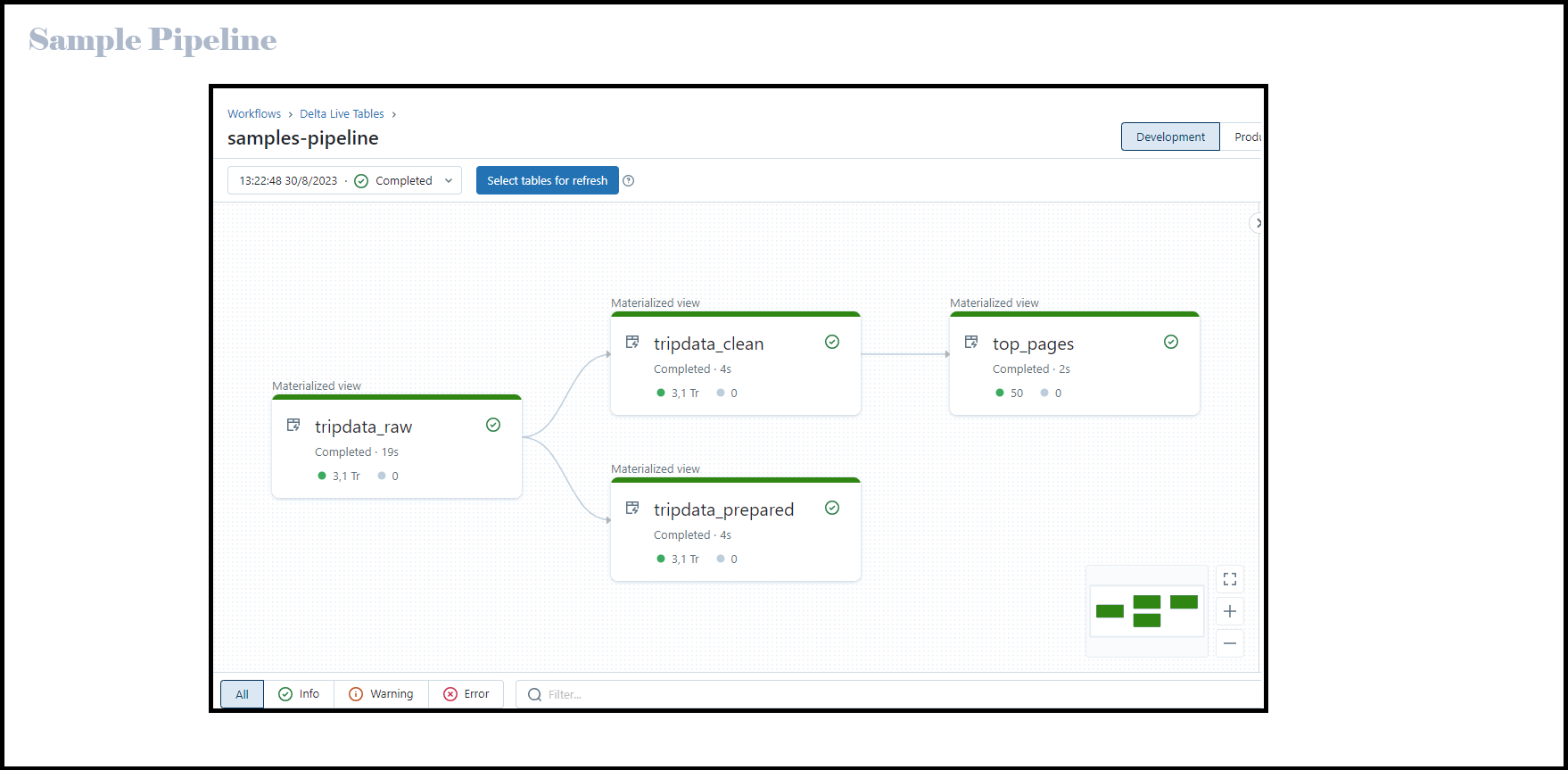 Delta Live Tablesのパイプラインとは、
Delta Live Tablesのパイプラインとは、
Delta Live Tablesでデータ処理ワークフローを構成して実行するためのリソースです。
パイプラインには、PythonやSQLのソースファイルで宣言されたマテリアライズドビュー※1と
ストリーミングテーブル※2が含まれます。
パイプラインでは、SQLクエリやPython関数を使ってDelta Live Tablesのデータセットの内容を指定できます。
パイプラインを作成する手順は、「Delta Live Tablesのパイプラインを実装してみよう」で説明します。
※1マテリアライズドビューとは、ビューの結果をあらかじめテーブルとして保存する仕組みです。
アップストリーム データセット(パイプライン内のテーブルが依存するデータソース)の変更を反映するように
クエリ結果が再計算され、最終の結果と一致することが保証されます。
データが更新された時に最新の結果に基づいてテーブルが自動的に更新されるということです。
※2ストリーミング テーブルとは、ストリーミングまたは増分データ処理の追加サポートを備えた Delta テーブルです。ストリーミング テーブルは、新しいデータが到着したときに結果を段階的に計算できるため、更新のたびにすべてのソース データを完全に再計算しなくても結果を最新の状態に保つことができるため、大規模な変換にも役立ちます。
4.SQLでパイプラインを宣言する手順
Delta Live Tablesのパイプラインを宣言すると、
データに対して行う変換処理をPythonやSQLのソースファイルで定義することができます。
【準備】ノートブックを開く
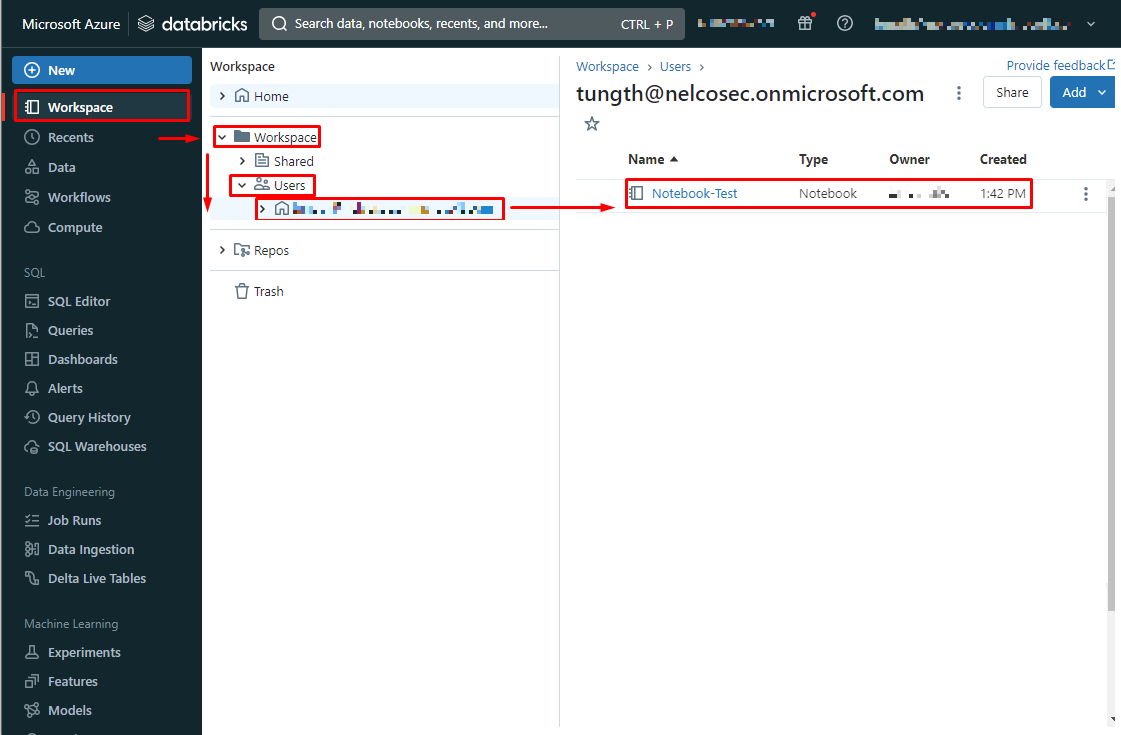
〇既存のノートブックを開く
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、サイドバーを展開します。
③Workspace > Workspace > Users >自分のユーザー名 > 使用するノートブック を選択します。
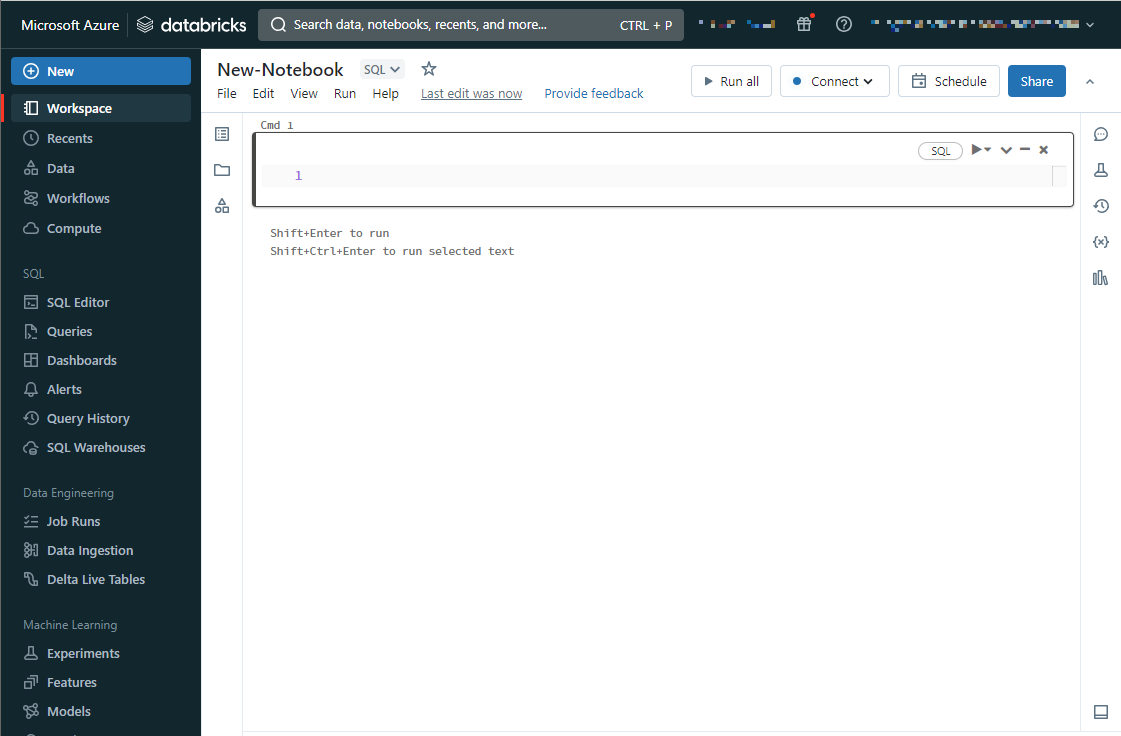
〇新規のノートブックを作成する
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、サイドバーを展開します。
③+New > Notebook を選択します。

④作成したノートブックが開かれます。
4-1.オブジェクト、またはストレージ内のファイルからパイプラインを宣言する
【文法】
CREATE OR REFRESH LIVE TABLE [テーブル名]
COMMENT “[コメント]”
AS SELECT * FROM [ファイル形式].[ストレージアカウント名]/[コンテナ名]/[フォルダー名]/[ファイル名]
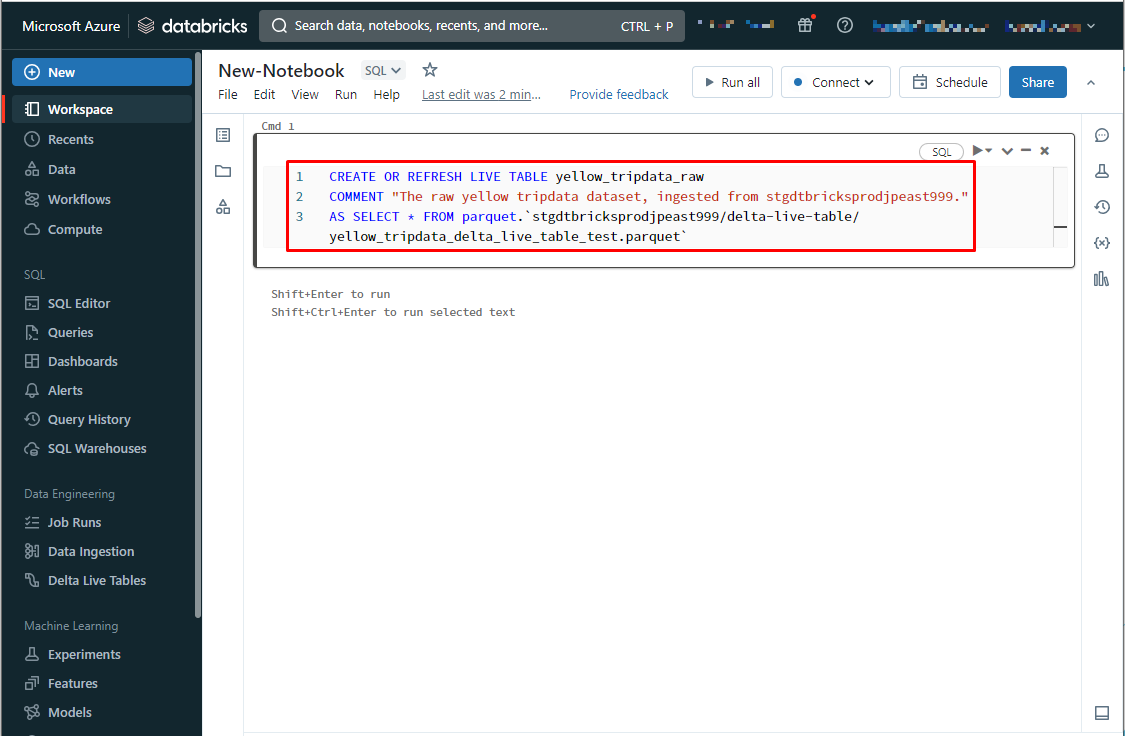
【例】ストレージアカウントのParquetファイル「yellow_tripdata_delta_live_table_test.parquet」
というデータを定義する
|
1 2 3 |
CREATE OR REFRESH LIVE TABLE yellow_tripdata_raw COMMENT "The raw yellow tripdata dataset, ingested from stgdtbricksprodjpeast999." AS SELECT * FROM parquet.`stgdtbricksprodjpeast999/delta-live-table/yellow_tripdata_delta_live_table_test.parquet` |
4-2.アップストリーム データセットからパイプラインを宣言する
【文法】
CREATE OR REFRESH LIVE TABLE [テーブル名](
CONSTRAINT [カラム] EXPECT ([条件])
)
COMMENT ” [コメント] ”
AS SELECT
[カラム名] AS [新しいカラム名]
FROM [参照するデータセット]
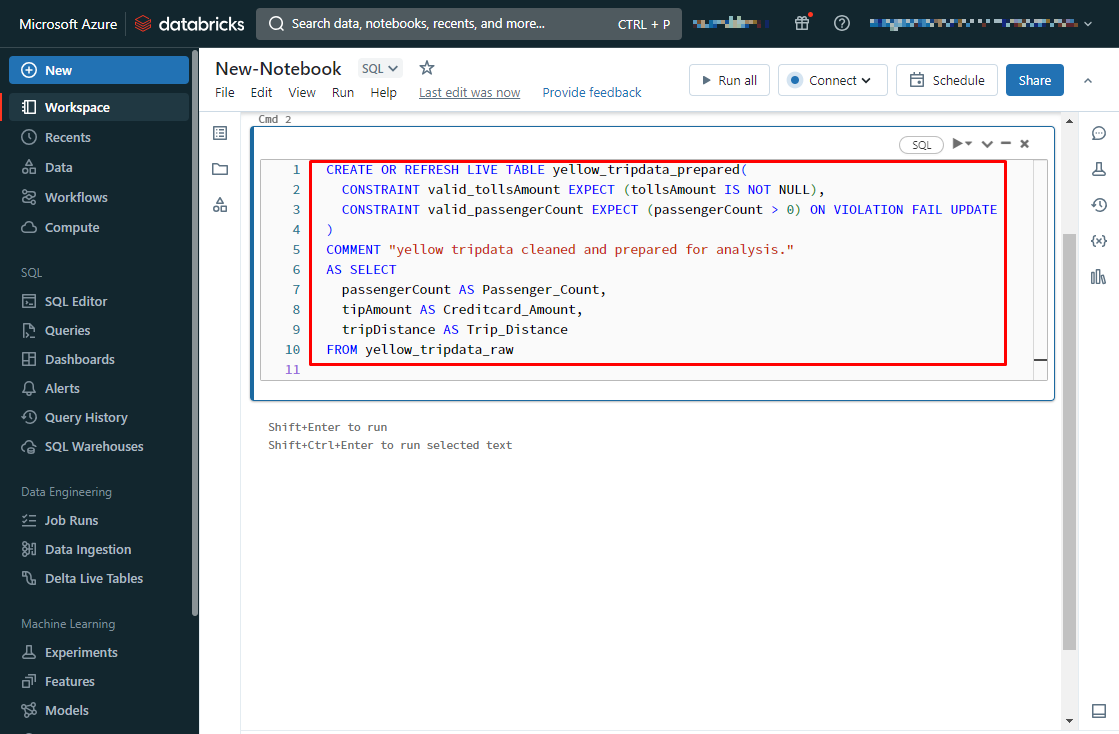
【例】作成されているデータセット「yellow_tripdata_raw」からデータを取得し、
新たなデータセットを作成する
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR REFRESH LIVE TABLE yellow_tripdata_prepared( CONSTRAINT valid_tollsAmount EXPECT (tollsAmount IS NOT NULL), CONSTRAINT valid_passengerCount EXPECT (passengerCount > 0) ON VIOLATION FAIL UPDATE ) COMMENT "yellow tripdata cleaned and prepared for analysis." AS SELECT passengerCount AS Passenger_Count, tipAmount AS Creditcard_Amount, tripDistance AS Trip_Distance FROM yellow_tripdata_raw |
参考URL:
https://learn.microsoft.com/ja-jp/azure/databricks/delta-live-tables/sql-ref
5. まとめ
本記事ではAzure DatabricksのDelta Live Tablesの基本について説明しました。
この連載では、Azure DatabricksのDelta Live Tablesの基本から実行手順について説明しています。
是非合わせてご覧ください。
第1回:Delta Live Tablesの基本を知ろう(今回)
第2回:Delta Live Tablesのパイプラインを実装してみよう
第3回:Delta Live Tablesのデータの品質管理とは?
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら