Data+AI Summit 2023 基調講演 Day2 (6/29)
powered by 日商エレクトロニクス

こんにちは、日商エレクトロニクスのマーケティング担当 鈴木です。
この記事では米国時間6/29の 基調講演(Keynote) Day2をまとめていきます!Day2は、感覚として技術の話が多く聞こえました。
Day1と同じく3時間休憩なしの長丁場でしたので、ちょこちょこ更新していこうと思います。
Data+AI Summit 2023の公式サイトはコチラ >
Data+AI Summit 2023 まとめサイト powered by 日商エレクトロニクスはコチラ >
●こんな方におススメ
- Data+AI SUMMIT 2023 基調講演の内容を日本語でササッと理解したい
目次
1. 前提
まずはdatabricks社の考え方を整理します。
この後の話や製品アップデート情報が頭に入りやすくなるかな、と思います。
・
AIは着実に発展しており、それは人間の生産性向上やさらなる価値の創造につながる。
しかし技術だけではそれを達成するのは難しく、誰もが同じように使える「民主化」を実現する必要がある。(インターネットは世の中を大きく変えましたが、その前に”専門知識が無くても誰でも気軽に利用できる”状態になっていますね。)
その中でdatabricks社は
データ:すべての従業員に民主化
AI:すべてのプロダクトで民主化
を目指しています。
・
それでは、次からはキーノート2日目の内容です!
2. 今後のAIの発展について
最初のセッションは、Andreesen Horwitの共同創設者で、NetScaleの創始者であるマークとdatabricks CEOアリの対談です。
昨今のAIの発展について、今後AIで成功するために必要なことを話し、最後にはプログラマに当てた激励のメッセージもありました。
ここ数年で、突然AIがブレイクした、なぜか。
それは、メディアが集約され、AIがあらゆる情報を学習可能になったからだ。
(メディアは、新聞→ラジオ→テレビ→インターネットという風に進化してきていますが、インターネットはそれ以前の機能を包含していますよね。)
そしてまたAIも1つにまとまってきている。(テキスト、画像、音声、などの複数の情報を一度に処理することが可能なマルチモーダルAIが普及していることに表れていますね)
このことから、AIは次の発展を誘発しており、シンギュラリティに向けて進んでいることがわかる。
爆発的に進展するわけではないが、物事は徐々に改善され人間にとってのユートピアを実現すると考えられる。
しかし一方で、AIはターミネーターと同じようにただ目の前の目的に向かって進むため、最終的にはそれがディストピアにつながる可能性がある。
AIをユートピアに向かわせるために、コグニティブインテリジェンス(知性)に期待されている。
人間は知性があることで平和になり、バイアスがなくなり、成功してきたためだ。
また、今後、現在のようなプログラミングは無くなるのだろうか?
正確なコードが必要なのだろうか?プログラマはどうなるのか?
今後も正確なコードはまだ必要であるが、プログラマは「AIのマネージャー」になっていくだろう。AIはあくまでcopilotである。優秀なプログラマは、AIによって生産性が上がる。
また、プログラミングができなくてもプログラマになれる未来は近い。
マシンが人間から仕事を奪うことにおびえる人もいるが、人々はさらに新しい価値のあるミッションを実行できるようになるだろう。
しかし、それは短期間ですぐに実現できるわけでは無い。
キャリアを進めるには、コンピュータサイエンティストとしての決意、ビジョン、勇気が必要だ。即座に成果が出なくても、時間をかけて粘り強く進んでいこう。
3. Sparkの注目アップデート
Sparkの知名度が上がってきた。10億回ダウンロードされているほど。
その理由は、シンプルであること、インターネットがあればどこでも使えること、マルチパラダイムで可用性が高くOSS系システムにほぼ含まれていることだ。
特に、LangChain, Hugging Face, PyTorch, XGBoostにはネイティブsparkを利用している。
そして今の注目はSpark Connect、Pyson、A new Program Languageの3つである。
Spark Connect:どこからでもSparkクラスタへリモート接続できる
Spark Connectがこの度Spark3.4でGAした。
Spark Connectとは、クライアントとサーバーを分離したアーキテクチャで、あらゆるアプリケーションからSparkクラスタへのリモート接続を可能にし、どこでも実行できるようにする。このクライアントとサーバーの分離により、最新のデータアプリケーション、IDE、ノートブック、およびプログラミング言語がSparkにインタラクティブにアクセスできるようになった。
Spark Connectは、さまざまなプログラミング言語、アプリケーション、およびエッジデバイスに組み込むことができる。
オートコンプリート with Project Zen:入力補助で書き込みの負荷を軽減
いまやNo1プログラム言語とも言われるPython。
Databricks社は、Pythonの使いやすさを向上させることを目的としたProject Zenという活動を続けている。
その中で、特にインパクトを与えるのが「オートコンプリート」だ。
今まではパラメータが予測表示されるのみだったが、3.4ではさらに使いやすくなり、全文直接編集できるようになった。
また、コミュニティではPySparkの単体テストのフレームワークについてなど議論されているようです。
A new Program Language:日常言語でプログラムできる
「新しいプログラム言語として最もHOTなのは英語である」
という発言が話題に上がった。
英語(=日常言語)は新しいプログラム言語で、生成AIは新しいコンパイラ、Pythonは新しいバイトコードである。
これを実現する“English SDK”を発表する。
<デモ>
7日間の移動平均を出したい。
それにはいくつかの関数を利用することはわかる。しかし、具体的な文字の羅列を覚えているわけでは無いため、検索してCopy&pasteする必要がある。
英語(日常言語)ではやりたいことは表現できるのに、なぜコードに起こすために時間をかけなければならないのか?
English SDKで英語を使ってみましょう。
Spark APIをアクティベートしてGitHubよりダウンロードするだけで簡単に実行できる。
英語で実現したいことを入力すると…(赤い文字部分)
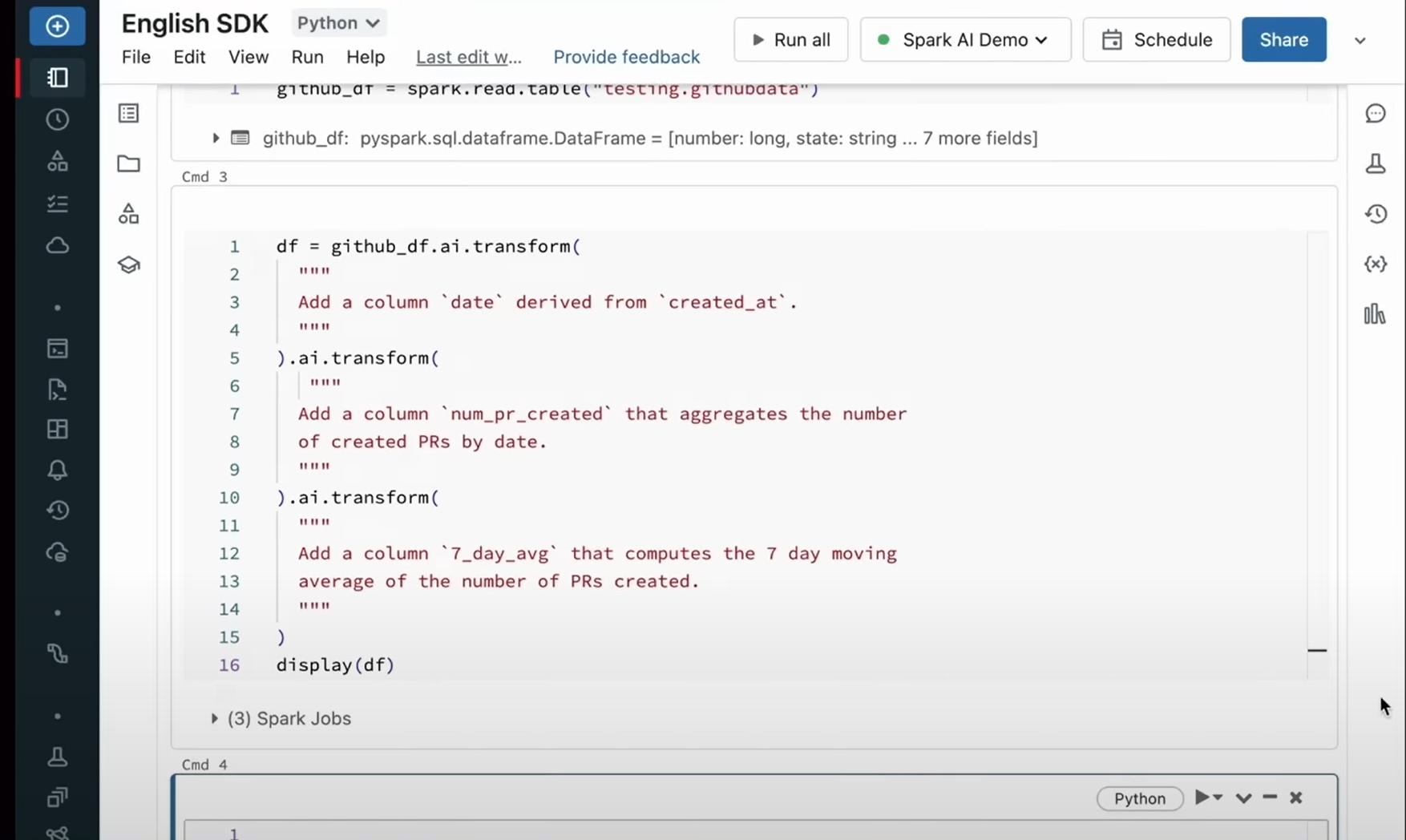
データが整理される。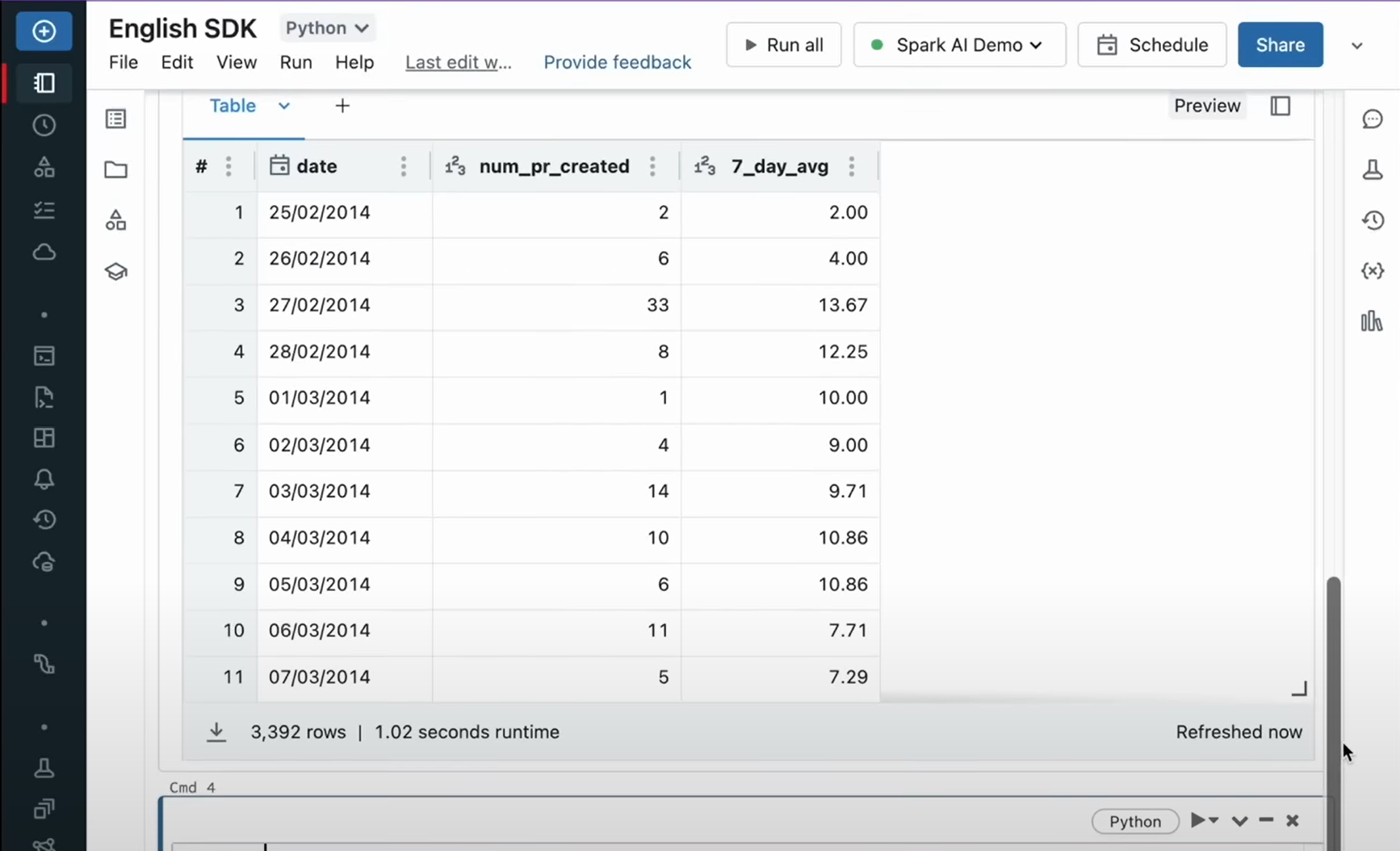
出てきたグラフを、さらに見やすくしたい。
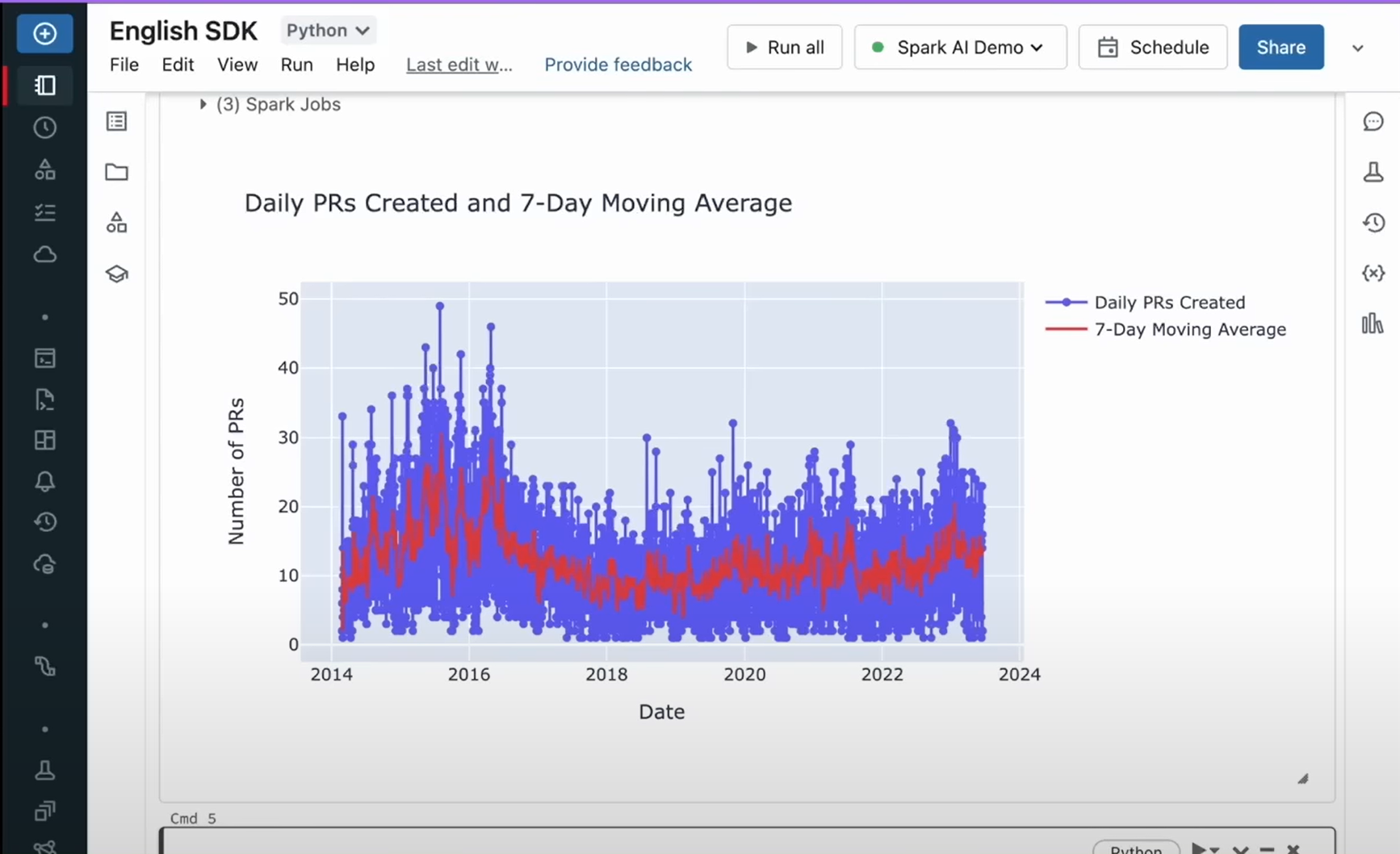
下記のようにオーバーレイしたグラフを作成したい。
英語で入力すると…
思ったとおりのグラフを作成できる。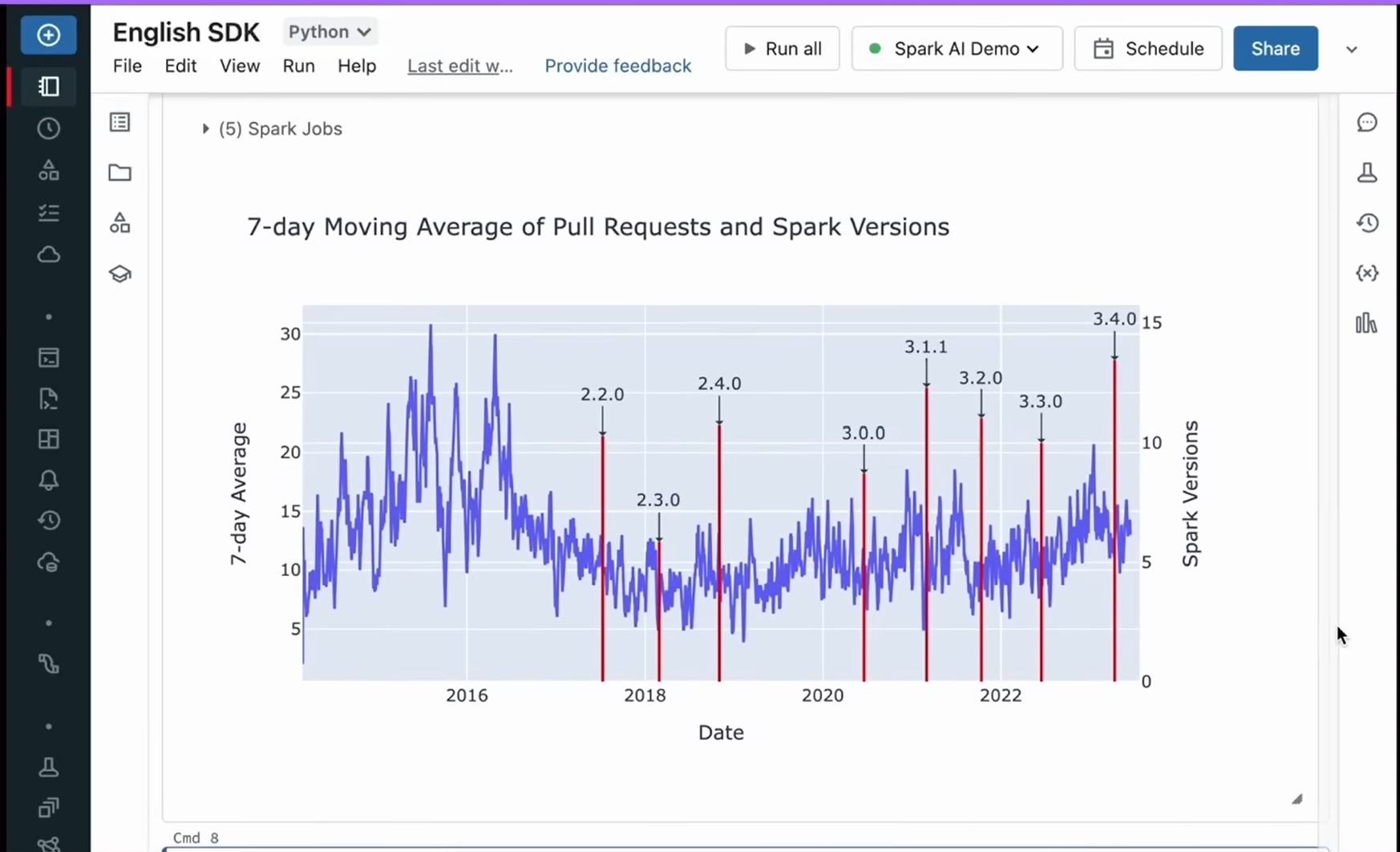
4. Delta Lake3.0について
DeltaLakeは多くの企業によって導入されている。その特長は、スピードが速いことである。
delta.rs
deltaプロトコルの実装をゼロからRustで記載したもの。
ネイティブコードであり、Pythonのような他のエコシステムにリンクさせることができる。
Delta Sharing:セキュアなデータ連携を実現
唯一のオープンなデータ共有プロトコルのこと。
これがあると、ベンダーロックインされること無く、安全にコンピュータプラットフォームを使用できる。しかも直接つなげるため不要なコピーを作らない。
アップデート情報としては、Oracleとtwilioへの対応、ストリーミングデータは全体をアップデートするのではなく差分のみ表示する、クエリ改善によるレイテンシ短縮、OAuth2.0対応、Cloudflare R2においてのアウトバウンド通信料金の無償化など。
Liquid Clustering;クエリ速度の向上を実現
Delta 3.0ではLiquid Clusteringという機能が追加された。これによりクエリ速度が最大2.5%向上する。
多重度の高いカラムでパーティションを行うと、ファイルサイズがそろわずI/Oのオーバーヘッドが課題となるが、小さいファイル同士を自動で結合することで、ファイルサイズを均一化するため。
5. AI研究者による対談
databricksの共同創設者でありCTOであるMatei ZahariaとAIの研究者たちがAIの最新動向や将来について語るパネルディスカッションが行われました。
参加者は下記です。
- Michael Carbin(MosaicML創立顧問、MIT電気工学・コンピュータサイエンス学科准教授)
- Dawn Song(UCバークレー電気工学・コンピュータサイエンス学科教授)
- Daniela Rus(MIT EECS教授、CSAIL所長)
彼らはそれぞれ自身の研究内容や現在取り組んでいることについて、また、AIの民主化や商業化についても議論されました。
・
参加者たちは、大量データを扱う大規模なモデルだけでなく、小規模なモデルや特定の分野に特化したモデルも重要視している。
AIとセキュリティの関連性についても話された。大きな言語モデルを使用することでセキュリティ向上やプライバシー問題が生じる可能性があることが指摘された。
AIの民主化や商業化についても言及され、より多くの人々がAIを利用しやすくなる可能性がある一方で、その利用方法に関する課題や倫理的な問題も存在することが指摘された。
AIの将来については、より多様なデータやモードを組み合わせたマルチモーダルなインタラクションが重要とされる一方で、AIモデルの内部動作や因果関係の理解も進める必要があることが強調された。
・
6. Databricks周辺ソリューション / 注目技術 / AIの将来 について
つづいて、データブックスの周辺ソリューションを提供する各メーカーよりそれぞれの製品や最新のデータAI技術の発展、注目技術についてデモを交えて紹介がありました。
DackDB
データ活用において何かがおかしい。少量のデータに対して大規模なインフラを用いている状態、いわゆる「雀を撃ち殺すのに大砲を使っている」という状態であるということが多いことだ。
この問題について、DackDBが解決策になりうる。
- Duck DBの特長は以下の通り。
- フットプリントが小さい。
- C++で構築されている
- パーケットファイルに直接格納できる
- 自動的にクエリを平行化できる
- 無償である
DuckDBはクライアントシステムではなく、Databaseがアプリケーション上にあるという仕組み。
これにより、analysisを手元ですばやく実行することにマッチする。
90GBのタクシーのデータが17億行ある場合、それを基本的なクエリで実行するのに3秒未満で実現できるのだ。
LangChain
LangChainとは、LLMアプリケーションを開発する際に活用できるオープンソースライブラリで、2022年10月からリリースされた。Pythonにも対応している。
言語モデルを使用して会社や個人ファイルに関する質問に答えることが可能であり、テキストから情報を抽出することも可能。
3つの領域に注目している。1つ目は検索性、2点目はコーディング中のエージェント、3点目はプロトタイプの評価。
LangChaiはdatabricksと組み合わせることができ、エンドツーエンドのアプリケーションを構築することができる。
MLとAIの時代においてデータ活用を支援し、多くの可能性を提供している。
Fireworks
Fireworksは開発のスピードを上げるプロダクションプラットフォームで、新世代のAI開発者が製品イノベーションに集中できるようになる。
生成AIの上で製品革新を加速することを目指し、実験プラットフォームおよびプロダクションプラットフォームが提供される。最新データ。個人データや評価レシピでカスタマイズし、コスト効率性も考慮した最先端のオープンソースモデルへアクセスすることが可能だ。
深層学習やAI技術が30年以上前から存在している事実も認識しつつ、既存技術からさらなる進歩を目指しているPyTorchもまた研究者が素早く探索・革新できるよう設計されている。
FireworksではJNL(Japanese Natural Language) モデル空間内競争力あり、これを通じて既存基盤技術の演算処理力向上や試験実施回数拡大に役立てることができるだろう。
Computer Vision
かつてFacebookのAI研究部門の責任者であり、UCバークレーで名誉教授を務めている、コンピュータビジョンの分野でパイオニアであるjitendra Malik氏がロボティクスにどう適用されるかについて最新の発展を語った。
ロボットやAIの領域ではまだ困難な問題が残っている。例えば、12歳の子供でもできる料理などの課題を完全に達成することは現時点では不可能だ。品質試験が難しいというAIのパラドックスも存在する。
ディープラーニングや大量データ処理が成功への重要なカギだと考えられている。
例えば、足元にある岩を恐れるような(=臨機応変な対応をする:デモで、その場の状況に応じて臨機応変に障害物をうまく超えているロボットの話があった)方法が研究されている。
これには、子供の学習段階も参考にされている。
乳児期から始まって多感覚段階へ進んで中物体へ反応するようになることや、子供自身が日々経験を積んで自己確信を得ていく様子が参考にされている。
このような、段階的な開発作業が重要であるのだ。
AIの将来についての対談
最後の対談では、元Google CEOのEric Schmidt氏がゲストとして参加し、AIの将来や特に生成AIについて議論しました。
シュミット氏は、新型インテリジェンス開発による大きな価値創造、市場の拡大の潜在性、そして自己宣伝能力向上などを挙げつつ、現代社会でのジェネラティブAIへの注目度が増加している理由を説明しました。
また、時間短縮とその結果生まれる正確さ要求も重要な要素であり、これらが進歩を加速させていると語りました。
生成AI」は「モデル」を見て用語が変わってきており、「Frontier Models」と「Specialized Models」がそれぞれ異なる理由で採用されていることが指摘されました。
最後に、当面では両方のビジネスモデル収益化手法が確立されず、それぞれの対応方法を考慮する政府間でも規制政策については議論が必要だ、と締めくくられました。
この記事を書いた人
-
マーケティング担当の鈴木です。
VDIやDataAI製品を中心に、セミナー、ブログ、メルマガなどで情報を発信しています!
よろしくお願いいたします_(._.)_