目次
1.はじめに
みなさん、こんにちは!
最近、Databricks社が公開したDollyについてご存知ですか?
このブログでは、Dollyについて紹介していきます!
2.Dollyとは何ですか?
Dollyは、Databricks社が開発したChatGPTのような、人間との対話行動を示すためにトレーニングされた大規模な言語モデル(LLM)です。

3.Dollyのメリット
Dollyは完全なオープンソースプラットフォームであり、ChatGPTなどの大規模な言語モデルを最大限に活用し、企業や顧客の特定の要件に合わせてカスタマイズすることができます。
つまり、独自のデータでモデルを微調整する自由度があり、独自のニーズに合わせた応答の理解と生成が可能です。例えば、新入社員向けのトレーニングシステムの作成や、会社のルールに関する疑問に答えるチャットボットなどがあります。
4.DatabricksでDollyの再現方法
Databricks環境でDollyを再現するには、以下の手順に従ってください:
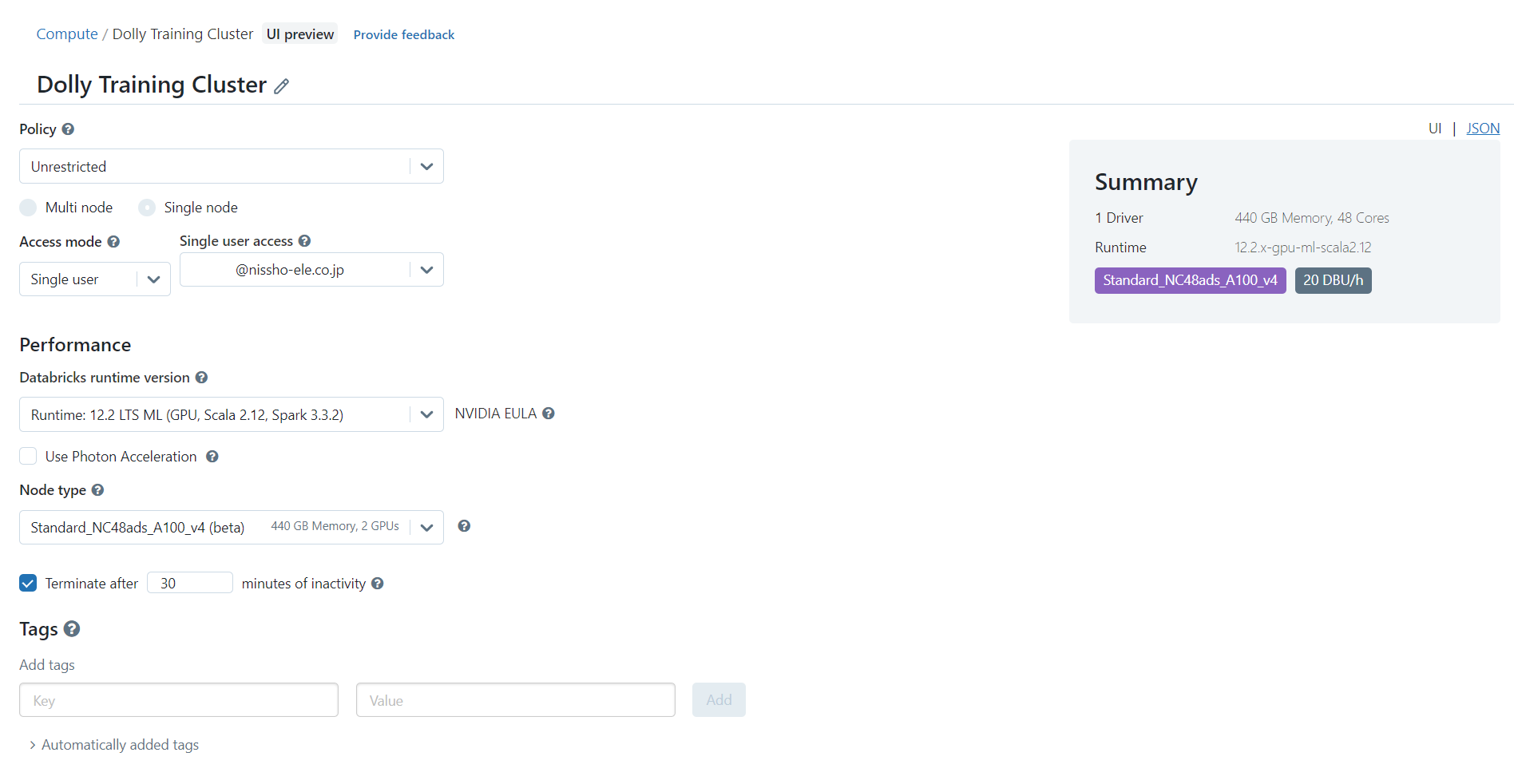
4-1. Databricksクラスタの作成
Dollyは大規模な言語モデルであり、かなりの計算リソースが必要です。Dollyモデルをロードするには、少なくとも400 GBのメモリとA100 GPUを備えたクラスタを使用することを強く推奨します。
 4-2.DollyをDatabricksにインポートする
4-2.DollyをDatabricksにインポートする
Databricks社はDollyの公式のGitHubリポジトリをリリースしています。以下のURLで見つけることができます。(Link)
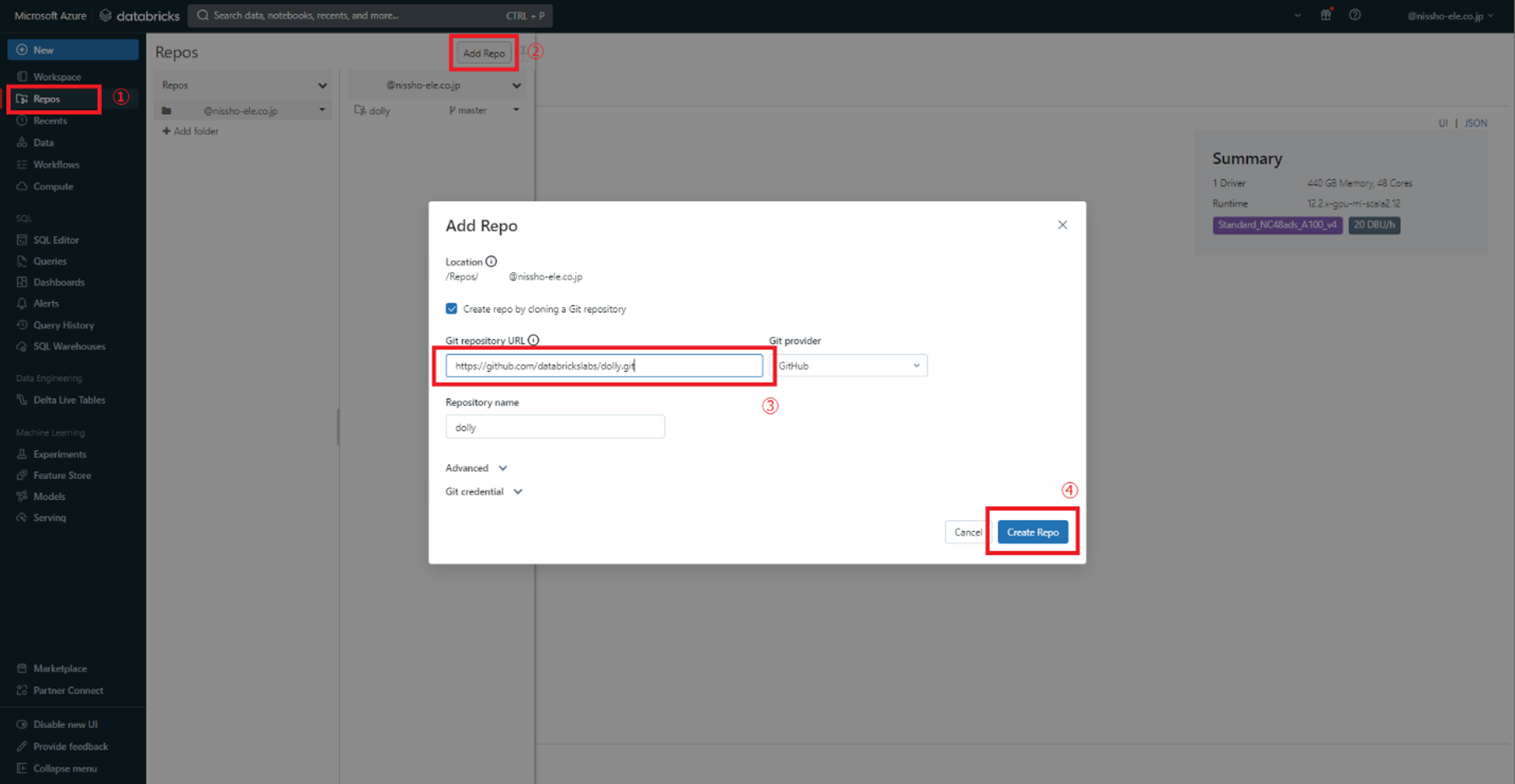
Databricks環境のリポジトリに追加します。
4-3.プレトレインモデルのロードとテスト
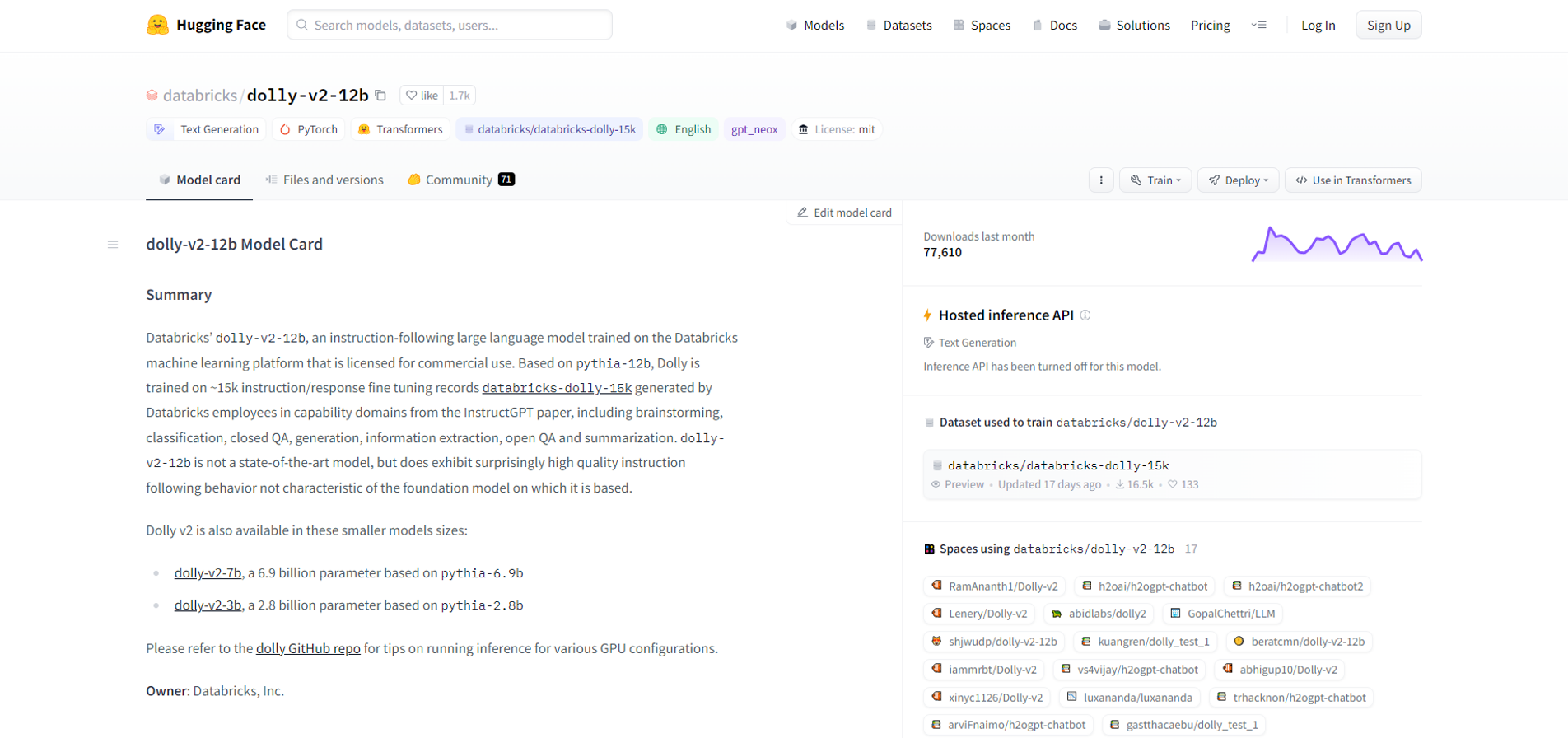
Databricks社は、”databricks/dolly-v2-12b“という名前のプレトレインモデルを提供しています。
Dollyは、”databricks-dolly-15k”という約15,000の命令/応答の微調整レコードでトレーニングされています。
“databricks/dolly-v2-12b”プレトレインモデルはHugging Faceにあります。(Link)
プレトレインモデルをロードしてテストするためには、以下のソースコードを使用することができます。
まず、ライブラリをインストールする
|
1 2 3 |
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2" %pip install accelerate[code_snippet_source id=3] |
次、プレトレインモデルをロードする
|
1 2 3 4 |
import torch from transformers import pipeline generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto") |
では、Dollyに質問をしてみましょう。
|
1 2 3 |
res = generate_text("Explain to me the difference between nuclear fission and fusion.") print(res[0]["generated_text"]) |
Output: Nuclear fission and nuclear fusion both result in the release of atomic nuclei, but the differences end there. For their investigation, scientists have created radioactive isotopes that emitted a particle or had a specific gamma signature that can be monitored. The most stable isotopes used for monitoring gamma emissions in nuclear fusion reactions are Ca, Cr, Fe, Na, and Zn. Fusion happens when two or more nuclei of lighter atoms, such as hydrogen, combine to form one or more nuclei of different atoms, such as oxygen. In some instances, especially when observing fusion in its most commonly used form, hydrogen fusion, the produced oxygen is extracted from the reaction site for use, admission, or resale to a third party. While this is occurring
素晴らしいですね!
では、日本語の質問をしてみます。
|
1 2 3 |
res = generate_text("機械学習について、説明して") print(res[0]["generated_text"]) |
Output: 機械学習とは、言語modelingやニューラ perform hidden Markov model review、機梋 generate types of learning open source projects classificationという調査のために出ている手法のことです。次のような感じで利用することもできます。Syntactically significant punctuation oneliners detectionのように、文章を分析して何らかの評定をしたい場合、機械を介して文章を見ることはできませんが、機� transmits not sufficient to recognize languagemodel.txt here was only a pesimistic estimate of the time taken to parse the sentence down to a form the model could actually understand. There is no way to read text to a model, but with transmitts not sufficient, it is not able to parse the sentences. However, there is a way to give the model something closer to a full transcription. Deep transcription a text to proper noun recognition example, here is how you would use it. *TEXT* translation at a phrase or sentence level is much closer to what a model would see can’t fully understand. *TEXT*
? Dolly-v2-12bは日本語の質問に対応することができないようですね。
“databricks-dolly-15k”は日本語のデータセットが不足しているかもしれないので、今回モデルを日本語のデータセットで再学習することを試みます。
5.Dollyを日本語のデータでトレーニングする方法
まず、Databricks-dolly-15kの日本語版を提供してくださった@taka_yayoiさんに感謝します。
taka-yayoi/databricks-dolly-15k-ja · Datasets at Hugging Face
上記のデータセットを使用してDollyモデルを再学習するには、次のようにDEFAULT_INPUT_MODELを “EleutherAI/pythia-2.8b” に変更し、DEFAULT_TRAINING_DATASETを “taka-yayoi/databricks-dolly-15k-ja” に変更します。
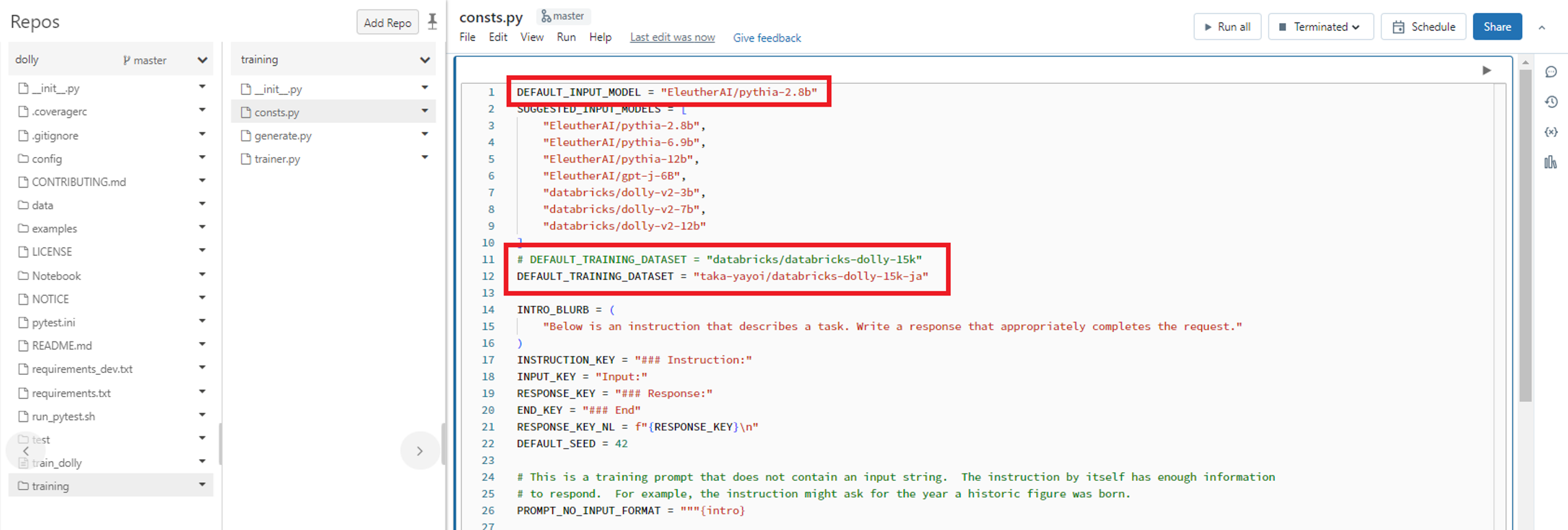
ノートブックtrain_dollyのCmd13のエポック数をデフォルトの2に設定しています。ウィジェットで、input_modelをEleutherAI/pythia-2.8bにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
!deepspeed {num_gpus_flag} \ --module training.trainer \ --input-model {input_model} \ --deepspeed {deepspeed_config} \ --epochs 2 \ --local-output-dir {local_output_dir} \ --dbfs-output-dir {dbfs_output_dir} \ --per-device-train-batch-size 6 \ --per-device-eval-batch-size 6 \ --logging-steps 10 \ --save-steps 200 \ --save-total-limit 20 \ --eval-steps 50 \ --warmup-steps 50 \ --test-size 200 \ --lr 5e-6 |
1.5時間ほどでトレーニングが終了しました。
では、モデルに問い合わせしてみます。
|
1 2 3 4 5 6 7 8 9 10 |
# Examples from https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html instructions = [ "猫のいいところは", ] # Use the model to generate responses for each of the instructions above. for instruction in instructions: response = generate_response(instruction, model=model, tokenizer=tokenizer) if response: print(f"Instruction: {instruction}\n\n{response}\n\n-----------\n") |
Instruction: 猫のいいところは
– 愛情深く、簡単に食事の時間を送り、主人に譲れる
– 自信、礼儀正しく、ボールハンティングが成績の高い
– 動物保護施設で保護された人のために愛情を示す
– 飼い主とは複数いる場合、偶然の相性いいかどうかに注意する
– サボることは特に愛情深く、かつ長い時間を過ごす人が多い
– 簡単に食事を行う
より良くなりましたね!!???
ただし、私たちの実験は最小のDollyモデル(pythia-2.8b)を使用して2エポックのみでトレーニングされたため、時々変な日本語が出てしまいました。
より多くのエポックとより大きなモデルでトレーニングすると、より良い結果が得られる可能性があります!
6.まとめ
DollyをDatabricksに展開し、カスタムデータセットでDollyモデルを再訓練する方法について説明させていただきました。
Dollyを触ってみたいという方の参考になれば幸いです!
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人
