1.はじめに
皆さんこんにちは。
この記事では、データリネージの一般的な使用例および、使用方法について説明していきます。
Databricks のオープン データ ストレージ レイヤーである Delta Lake は、SQLや機械学習 (ML) を使用してデータを処理できます。ただし、複雑なデータ構造、または頻繁に更新や変更が行われるデータベースの場合、データ セットを追跡してデータ可視化することは非常に困難になります。
データリネージを利用すれば、ライフサイクル全体にわたるデータ流れの可視化できます。
可視化のメリットとして以下のものがあります。
・ データセットがどこから来たか
・ データセットの構造はどのようなものか
・ データセットの変更が下流のデータセットにどのように影響するか
データリネージはUnity Catalog に保存されるデータセット間の関係を表示し、テーブル、カラム、ワークフロー間の関係を可視化するようにサポートします。
今回は、テーブルを作成し、テーブル間の関係を確立する具体的な例を提供し、データリネージを使用してテーブル間の関係をグラフとして可視化します。
2.前提要件
実施する際の前提条件は
・操作ユーザーは Azure Databrick ワークスペースにアクセス権限が必要です。
・操作ユーザーは、ノートブックの作成・実行権限があること。 作成していない場合、管理者に権限を付与してもらう様に依頼してください。
・ワークスペースで Unity Catalog が有効になっていること、またワークスペースが Premium プランのアカウントで起動されていることが必要です
・リネージキャプチャの対象となるテーブルは Unity Catalog メタストアに登録されている必要があります。
・テーブルまたはビューのリネージを表示するには、そのテーブルまたはビューに対する SELECT 権限がユーザーに付与されている必要があります。
・ノートブック、ワークフロー、ダッシュボード、パイプラインのリネージ情報を表示するには、ワークスペースのアクセス制御設定で定義されているこれらのオブジェクトに対するアクセス許可がユーザーに付与されている必要があります。
制限事項
・Delta テーブル間のストリーミングは、Databricks Runtime 11.3 LTS 以上でのみサポートされます。
・リネージ情報は 90 日間のローリング ウィンドウで計算されるため、90 日よりも前に収集されたリネージ情報は表示されません。
・Spark SQL データセットのチェックポイントを使用する場合、リネージはキャプチャされません。 Apache Spark ドキュメントの「 pyspark.sql.DataFrame.checkpoint 」を参照してください。
3.データの準備
まずは、データを準備するには次のように実施します。
テーブルを作成して、テーブル間の関係をノートブックで確立する。
データリネージを使用してテーブル間の関係を示すグラフを表示する。
① Databricksワークスペースにログインします。
② Databricks画面のサイドバーで「新規」をクリックして「ノートブック」を選択します。
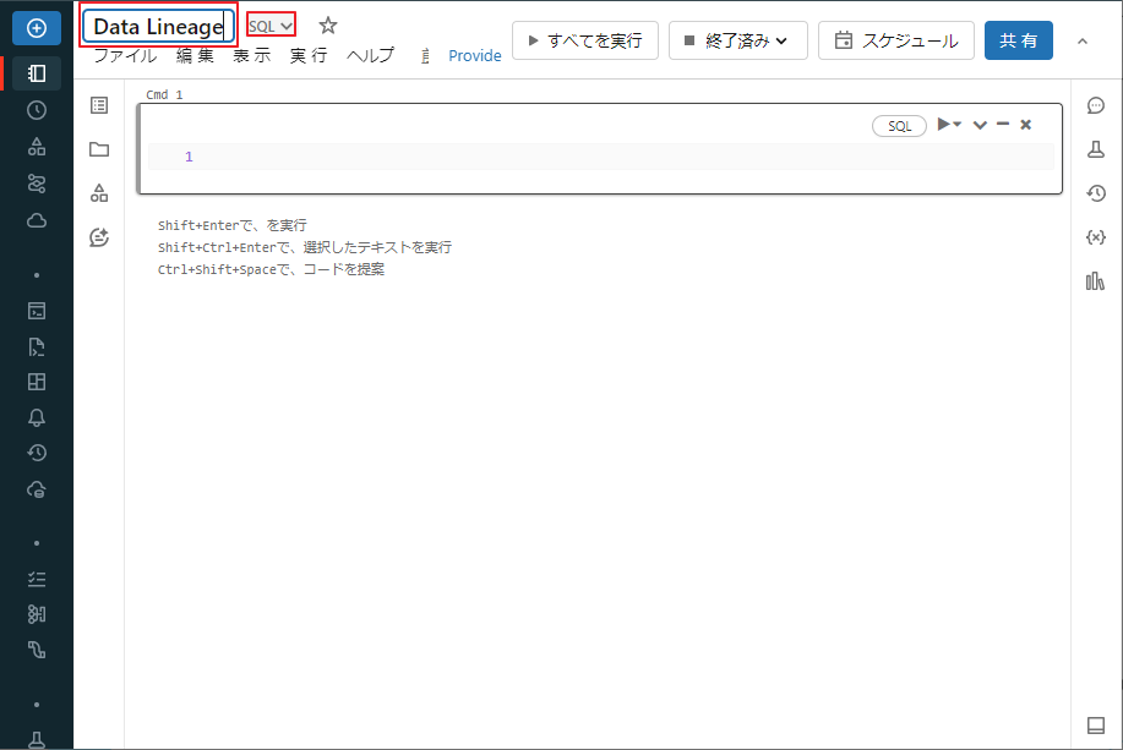
③ 新規作成したノートブック画面が表示されるので、ノートブックに名前を付け、デフォルトの言語として SQL を選択します。
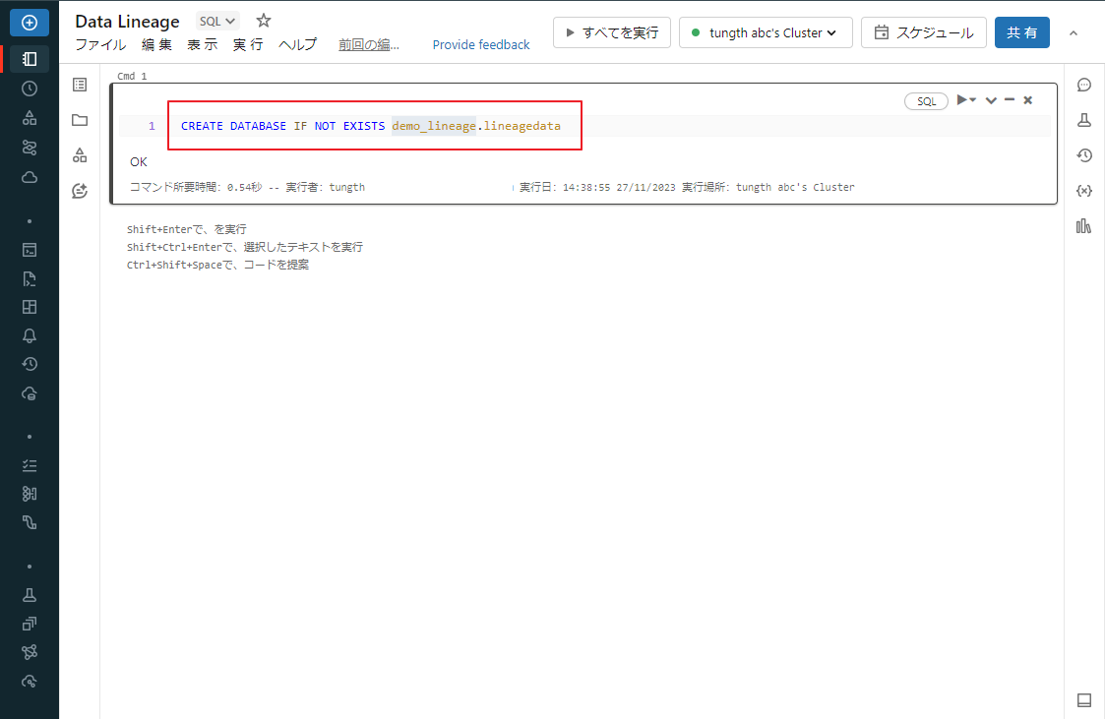
④ 以下のコードをコピーして、lineage_data カタログに「lineagedemo」というデータベース名を作成します。
|
1 |
CREATE DATABASE IF NOT EXISTS demo_lineage.lineagedata |
⑤「Shift」+「Enter」キーを押して、コマンドを実行します。
実行した後、指定したカタログにスキーマが作成されます。
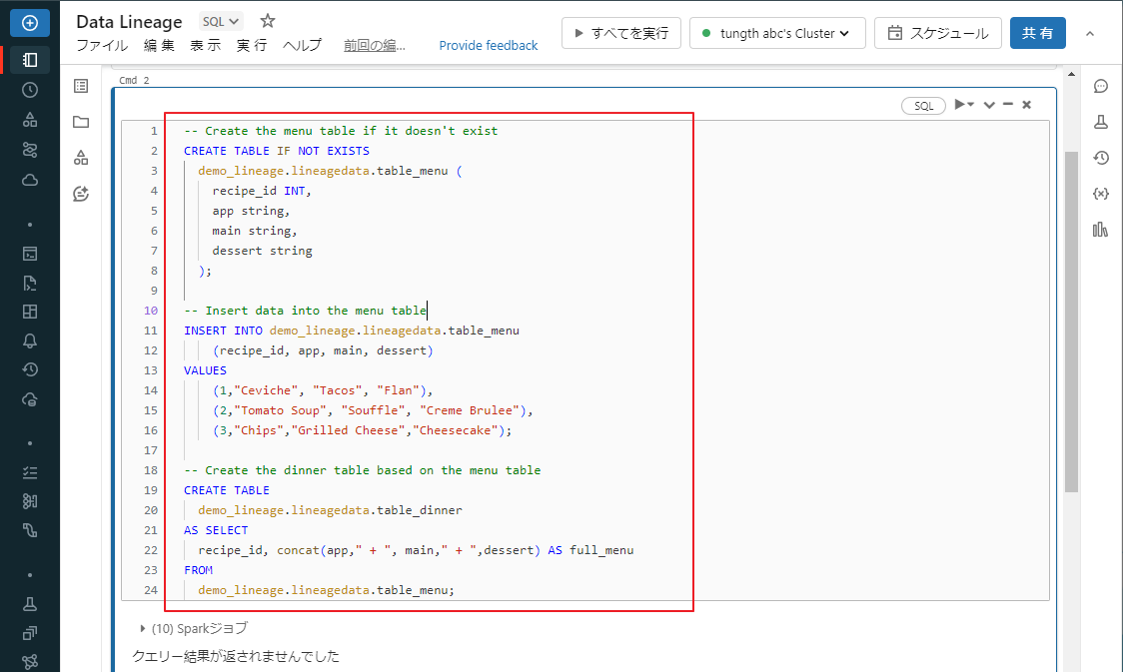
SQLクエリを使用して「menu」テーブルを作成します。 次に、「menu」データテーブルのデータを使用して「dinner」テーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Create the menu table if it doesn't exist CREATE TABLE IF NOT EXISTS demo_lineage.lineagedata.table_menu ( recipe_id INT, app string, main string, dessert string ); -- Insert data into the menu table INSERT INTO demo_lineage.lineagedata.table_menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); -- Create the dinner table based on the menu table CREATE TABLE demo_lineage.lineagedata.table_dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM demo_lineage.lineagedata.table_menu; |
「Shift」+「Enter」キーを押して、コマンドを実行します。
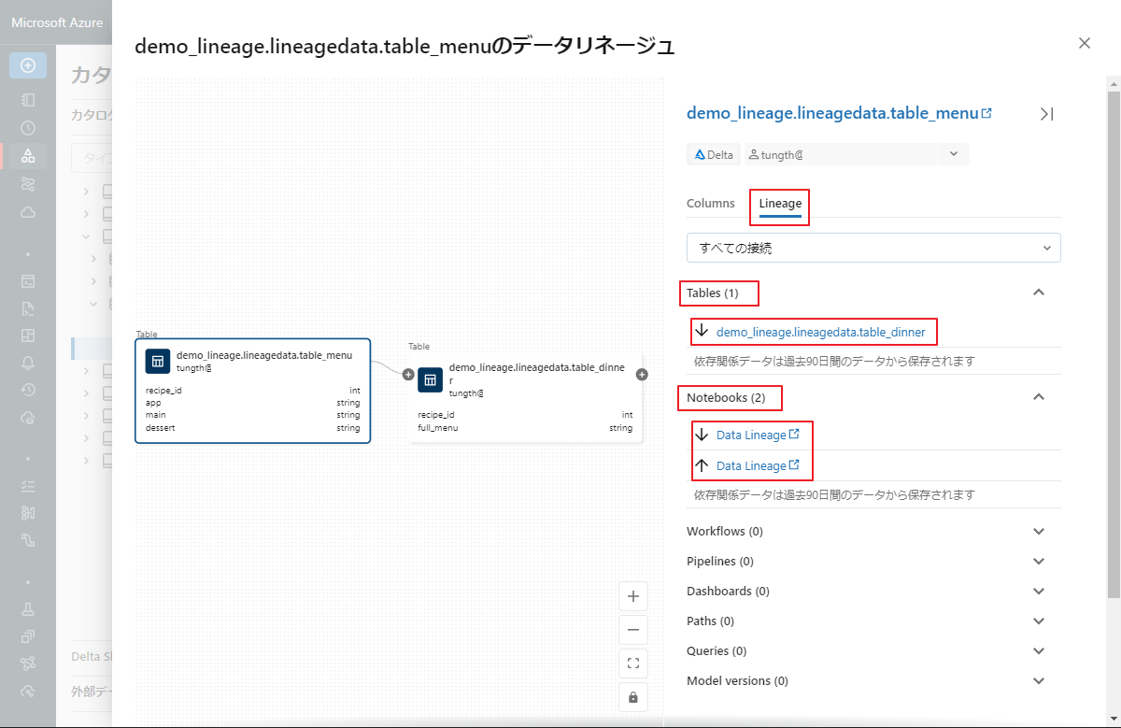
4.テーブルリネージの可視化
テーブルリネージの可視化は、システム内のデータ テーブル間の関係を表示する機能です。このテーブルから他のテーブルへのデータ流れをグラフとして可視化し、テーブル間のデータ変換も表示します。
これらのクエリによって生成されたテーブル レベルのリネージを表示するために Catalog Explorer を使用して、作成した2つのテーブル間の関係とリネージタブの下の他オプションを見てみましょう。
① サイドバーから「カタログ」をクリックします。
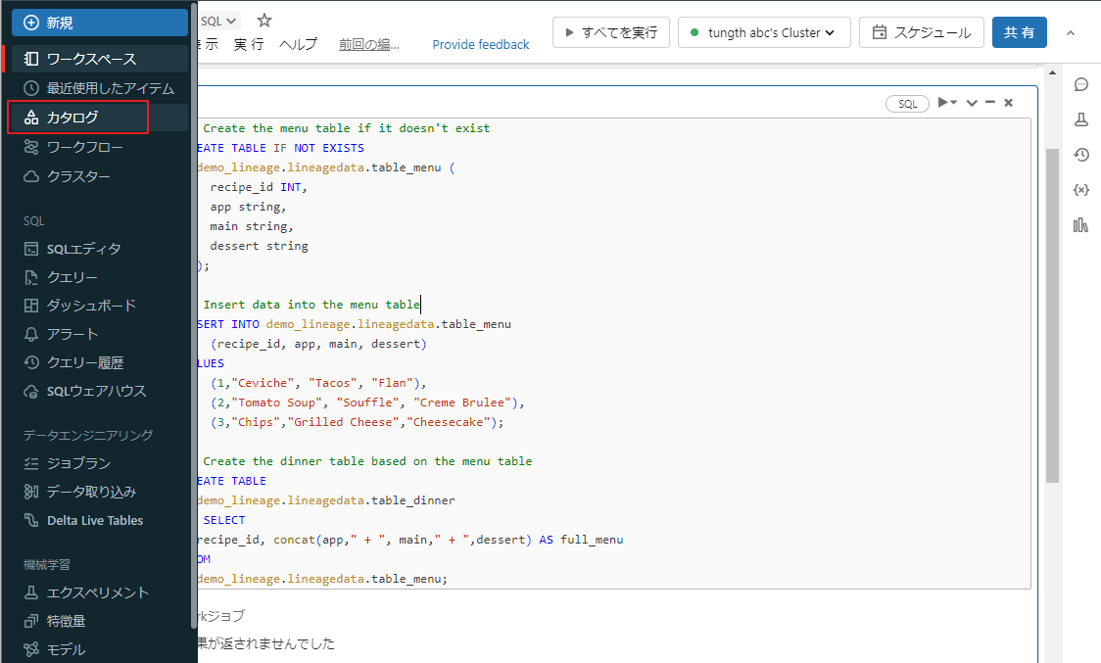
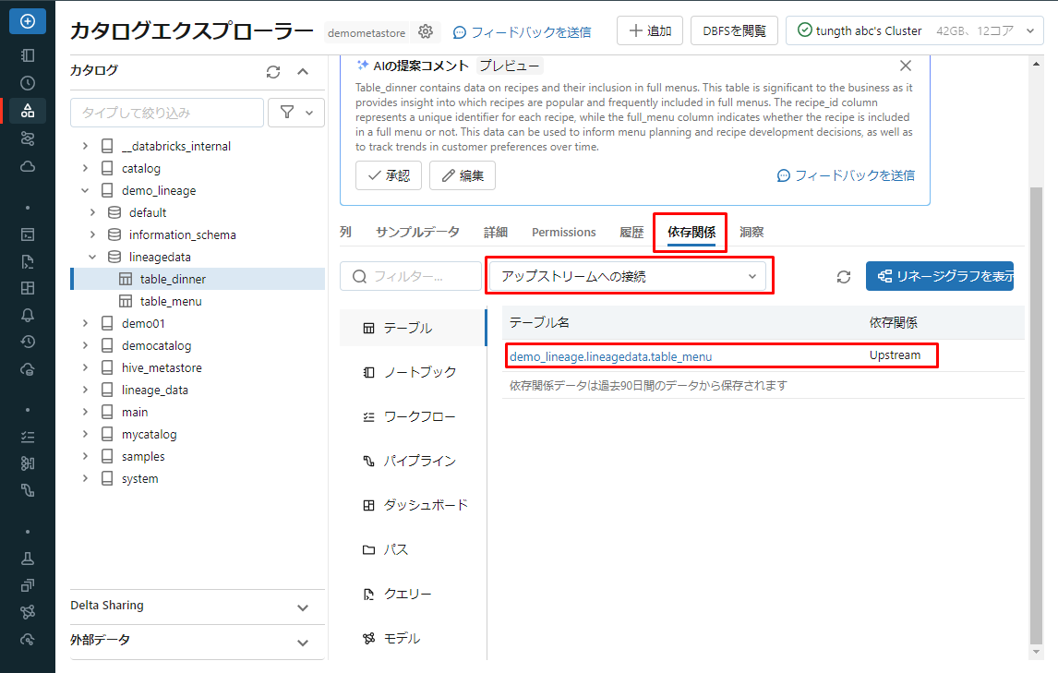
② カタログdemo_lineageのスキーマlineagedataのテーブルtable_menuをクリックします。
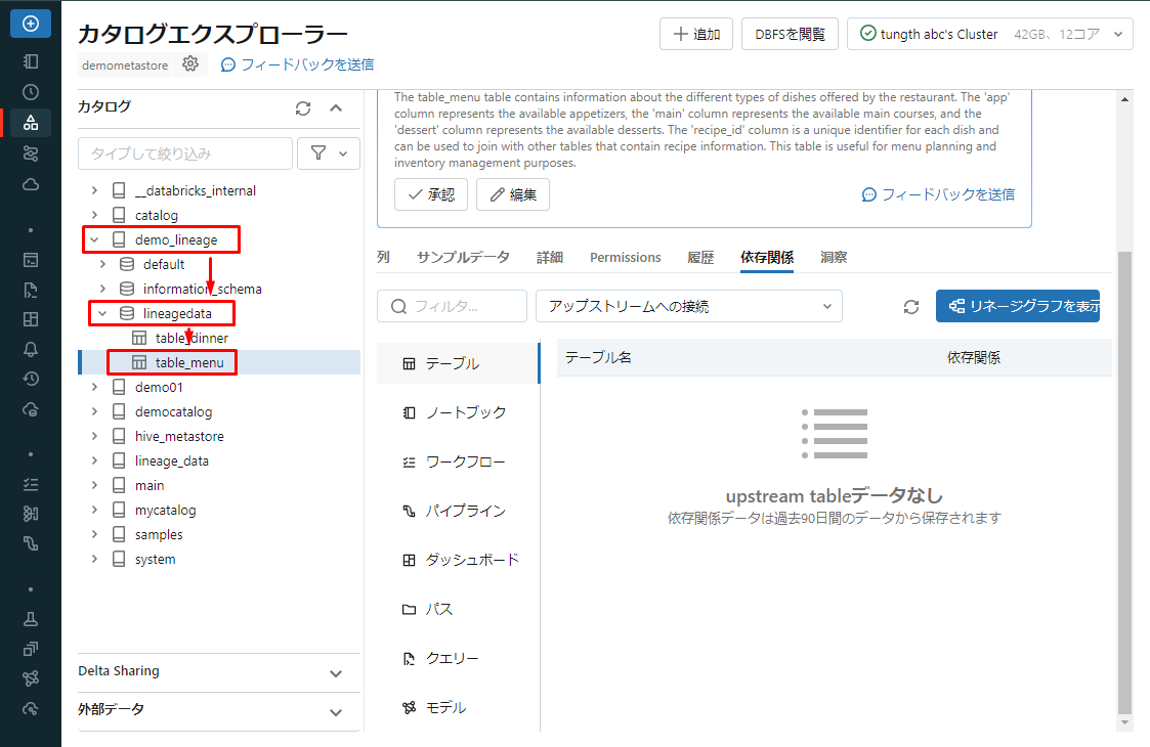
アップストリームへの接続とは、データのソースまたは発信元を指します。
テーブル table_menu の依存關係タブには、アップストリームのデータソースが記載されていません。 table_menu が開始点なので、テーブルを作成し、データを直接挿入するためです。 table_menu にデータを挿入する他のテーブルやプロセスはありません。
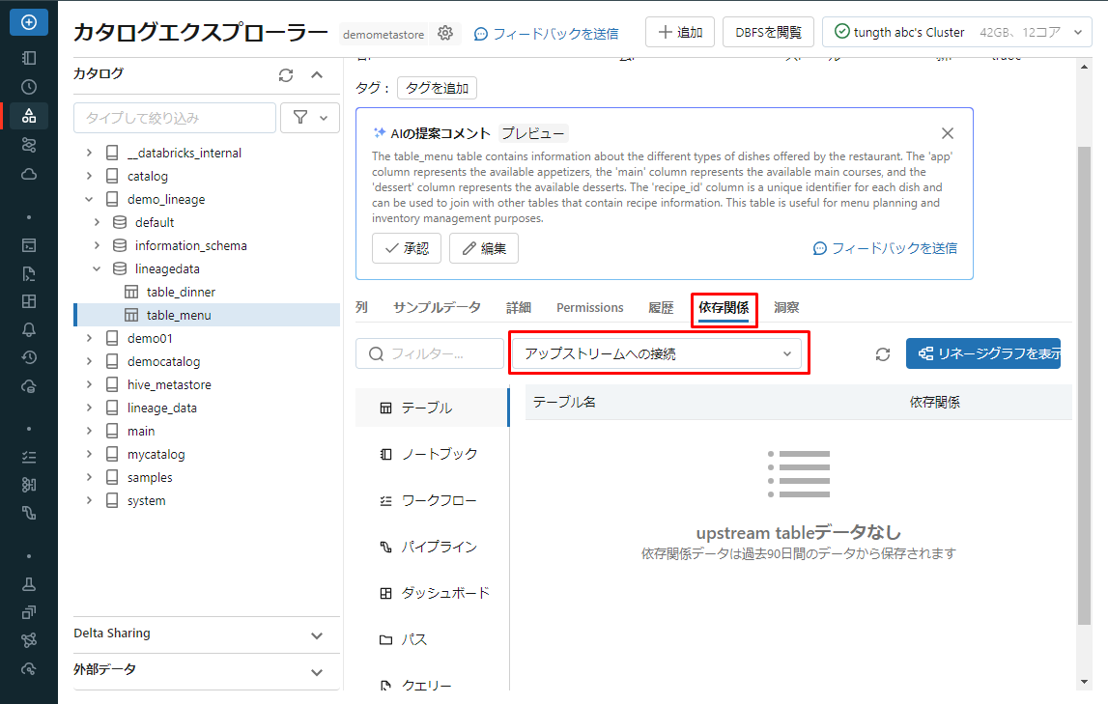
ダウンストリームへの接続とは、データが流れている先または目的地を指します。
テーブル table_menu の依存關係タブには、table_dinner がダウンストリームとして記載されています。これは、table_dinner が table_menu のデータから派生または依存されることを意味します。
このリネージ情報は、システム内のデータ フローを理解するのに役立ちます。
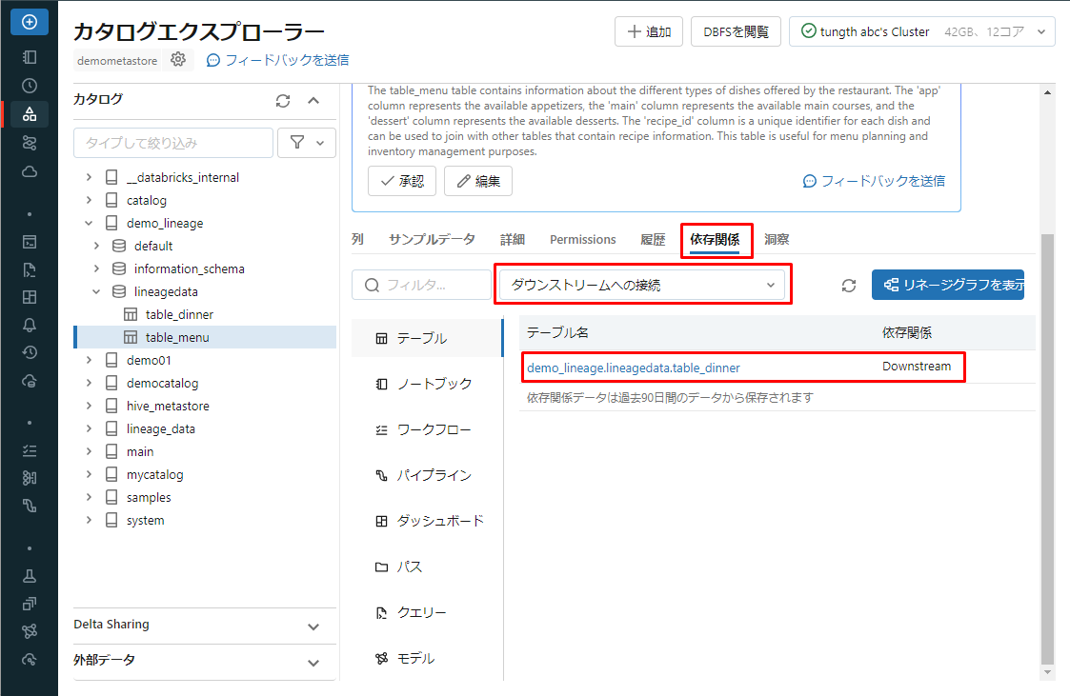
テーブル table_dinner の依存關係タブでも、同じ情報が表示されます。
table_menu はアップストリームとして記載されています。 これは、table_menu が table_dinner のデータのソースまたは起源であることを意味します。
③ テーブルのデータリネージのインタラクティブなグラフを表示するには、[See Lineage Graph] (リネージグラフの表示) をクリックします。
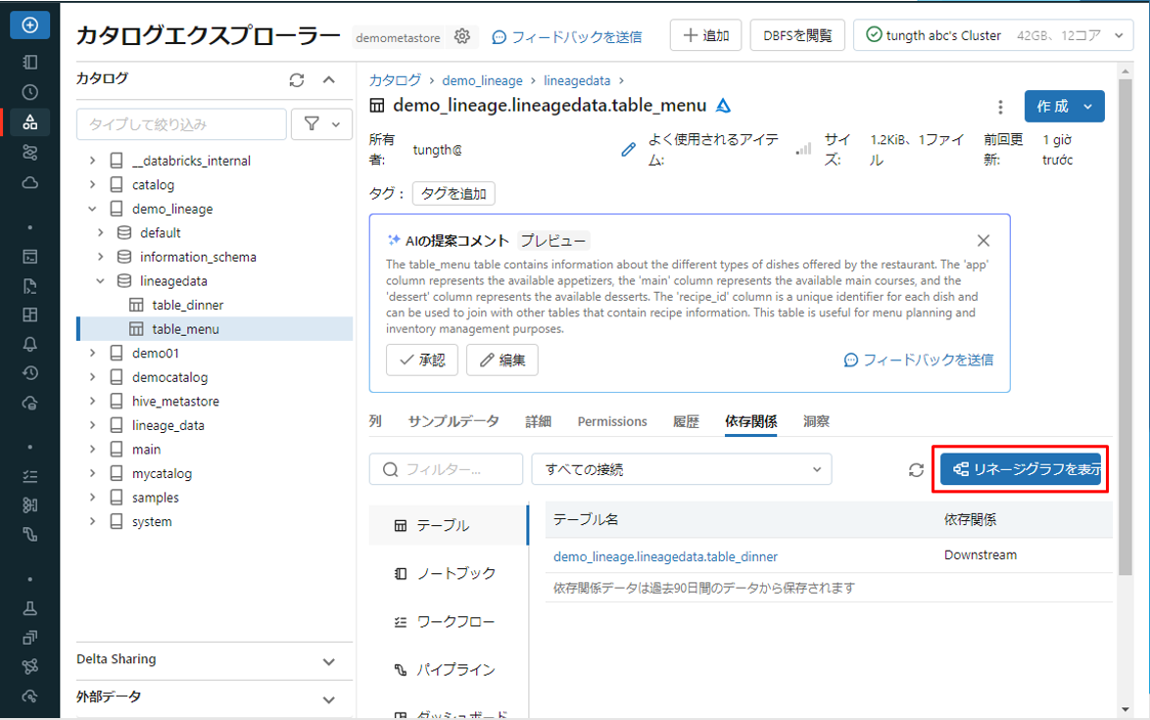
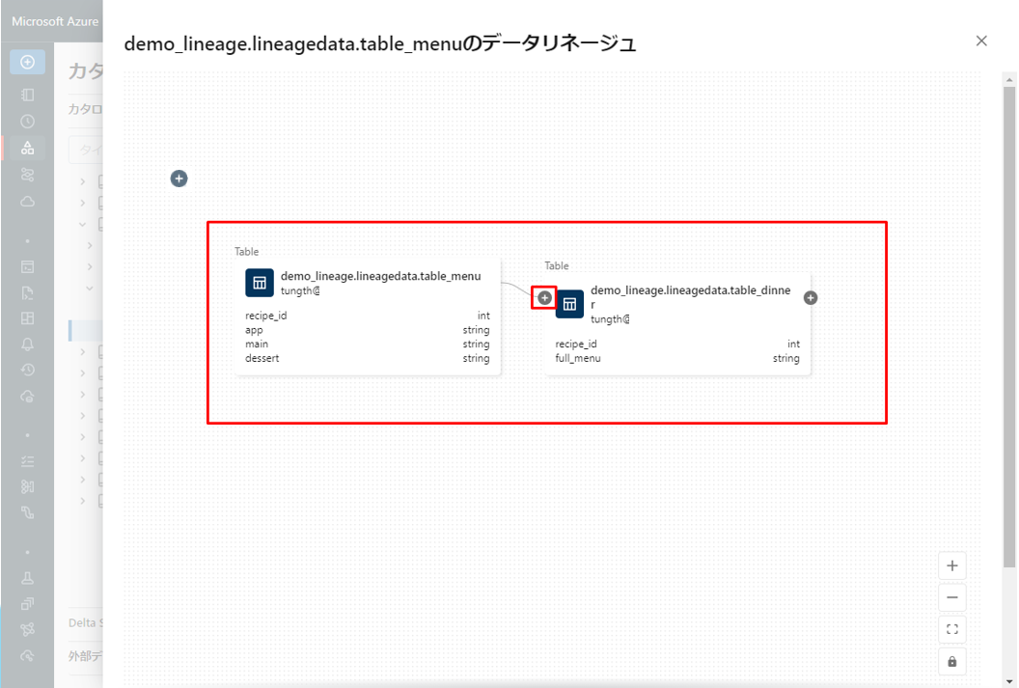
デファクトでは、1 つのレベルがグラフに表示されます。
④ ノードの ![]() アイコンをクリックすると、使用可能な場合は、さらに多くの接続を表示できます。
アイコンをクリックすると、使用可能な場合は、さらに多くの接続を表示できます。
⑤ リネージグラフ内の各ノードを接続する矢印をクリックして、[Lineage connection] (リネージ接続) パネルを開きます。
接続元と接続先のテーブル、ノートブック、ワークフローなど、その接続の詳細が [Lineage connection] (リネージ接続) パネルに表示されます。
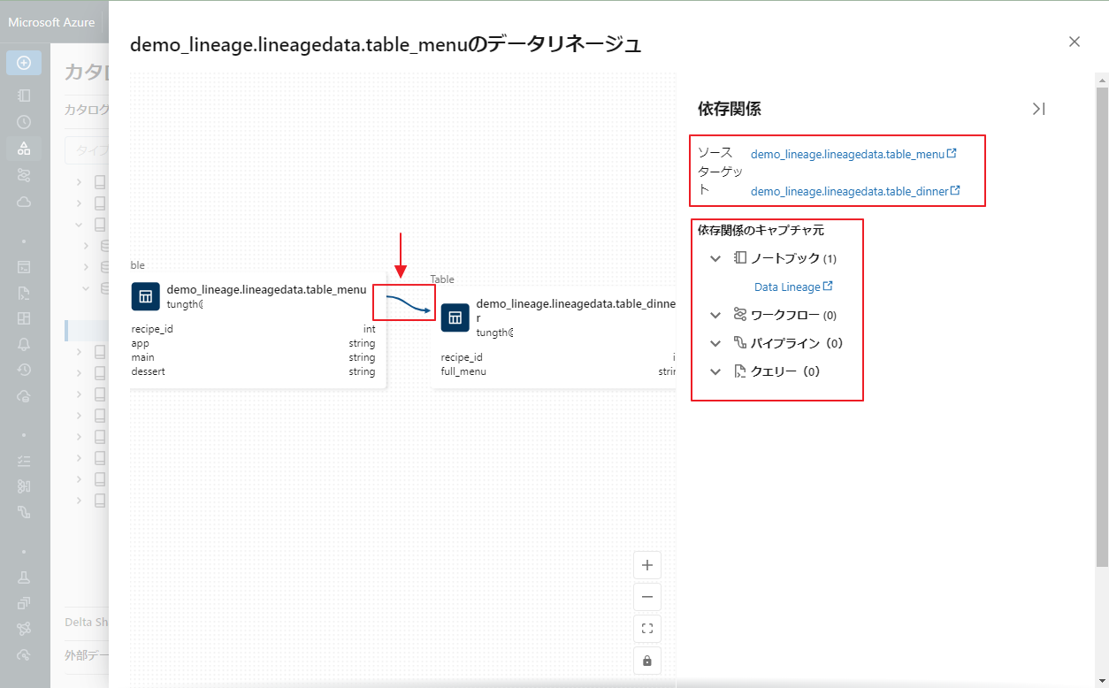
⑥ テーブルをクリックすると、[Lineage] タブで関連のテーブル、ノートブック、ワークフローなど及び、選択中のテーブルに対して上流または下流であるかどうかを確認できます。
5.カラムリネージの可視化
カラムリネージの可視化とは、システム内のデータ カラム間の関係を表示する機能です。全てのテーブルではなく、特定のカラムを集中し、データ処理中にカラム間でのデータ流れ及び、変換処理を監視できるようにします。
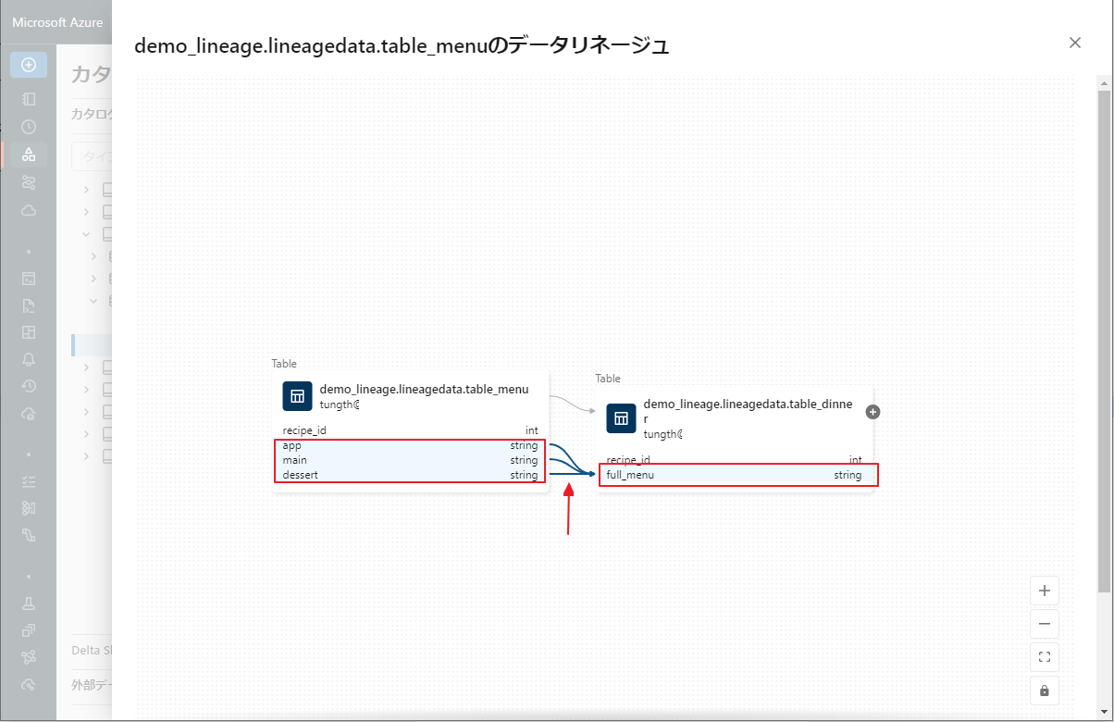
① 列レベルのリネージを表示するには、グラフ内の列をクリックして、関連する列へのリンクを表示します。
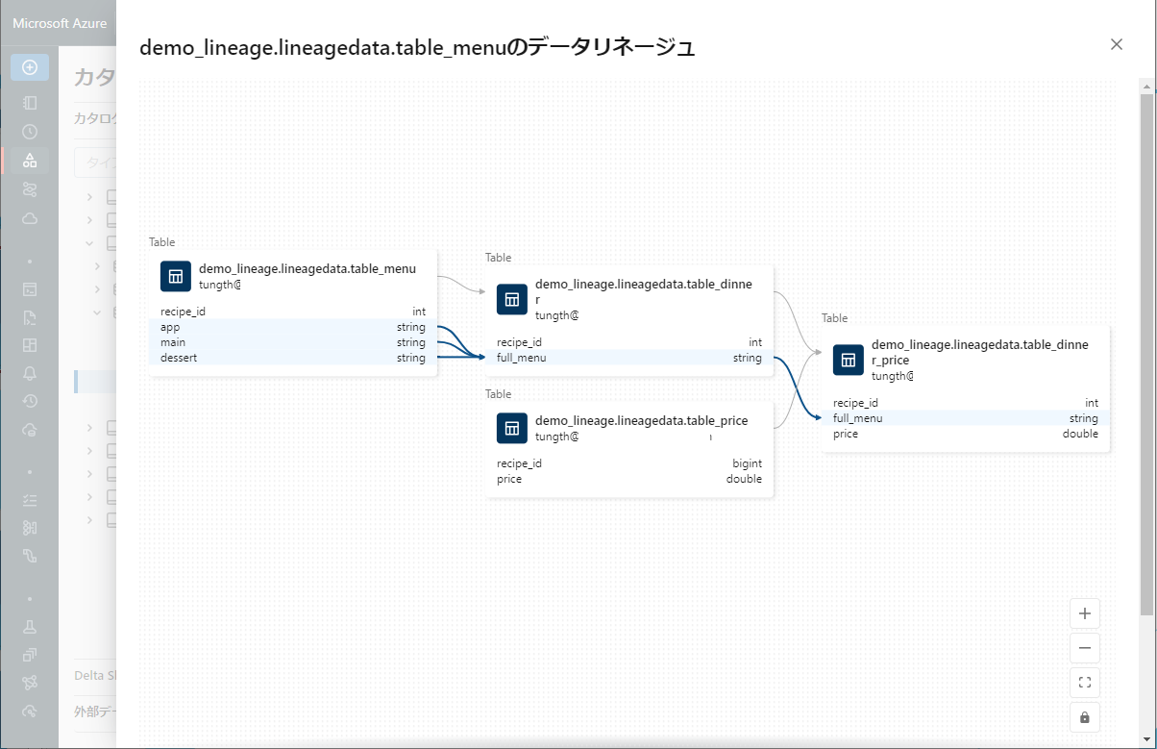
たとえば、”full_menu” 列をクリックすると、列の派生元のアップストリームの列が表示されます。
フローを見ると、table_dinner テーブルの「full_menu」列のデータが、table_menu テーブルの 3 つの列「app」、「main」、「dessert」から取得されていることがわかります。
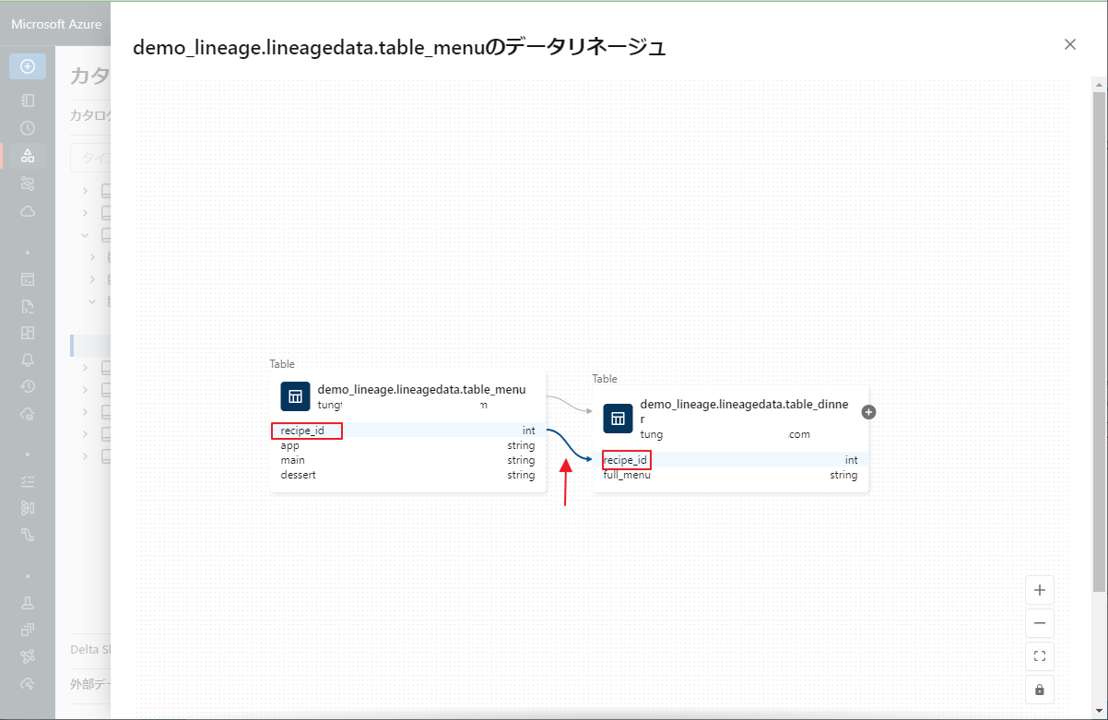
②「recipe_id」列をクリックすると、その列の派生元の上流列が表示されます。
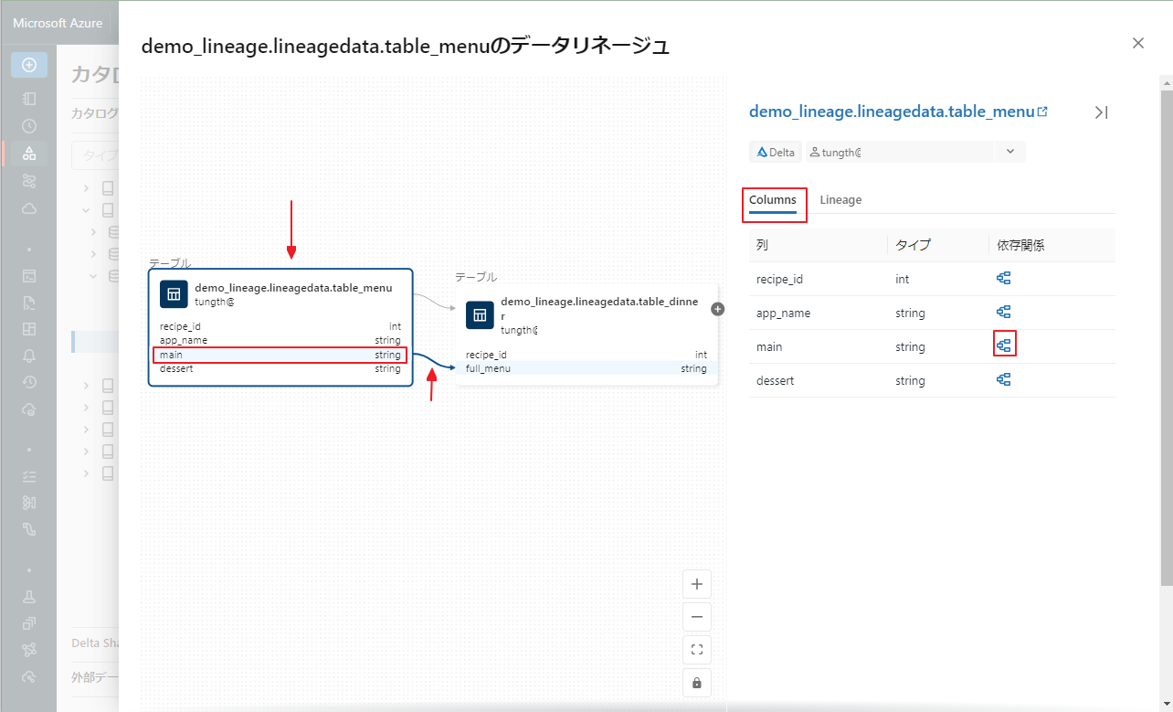
③ リネージ グラフの [Columns] タブで table_menu テーブルをクリックする時、demo_lineage.lineagedata.table_menu が表示されます。
④ ![]() アイコンをクリックすると、このテーブルの列と他のテーブルの列間の連携(あれば)を確認できます。
アイコンをクリックすると、このテーブルの列と他のテーブルの列間の連携(あれば)を確認できます。
Python などの別の言語を使用してリネージを作成および表示するには、次の手順を実行します。
⑤ 前に作成したノートブックを開き、新しいセルを作成し、次の Python コードを入力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
%python from pyspark.sql.functions import rand, round # Create a DataFrame with a range of values and a column named "price" df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") # Write the DataFrame to a table in the specified database and location df.write.mode("overwrite").saveAsTable("demo_lineage.lineagedata.table_price") # Read tables dinner = spark.read.table("demo_lineage.lineagedata.table_dinner") price = spark.read.table("demo_lineage.lineagedata.table_price") # Join the two DataFrames on the "recipe_id" column dinner_price = dinner.join(price, on="recipe_id") # Write the joined DataFrame to a new table dinner_price.write.mode("overwrite").saveAsTable("demo_lineage.lineagedata.table_dinner_price") |
⑥「Shift」+「Enter」キーを押して、コマンドを実行します。
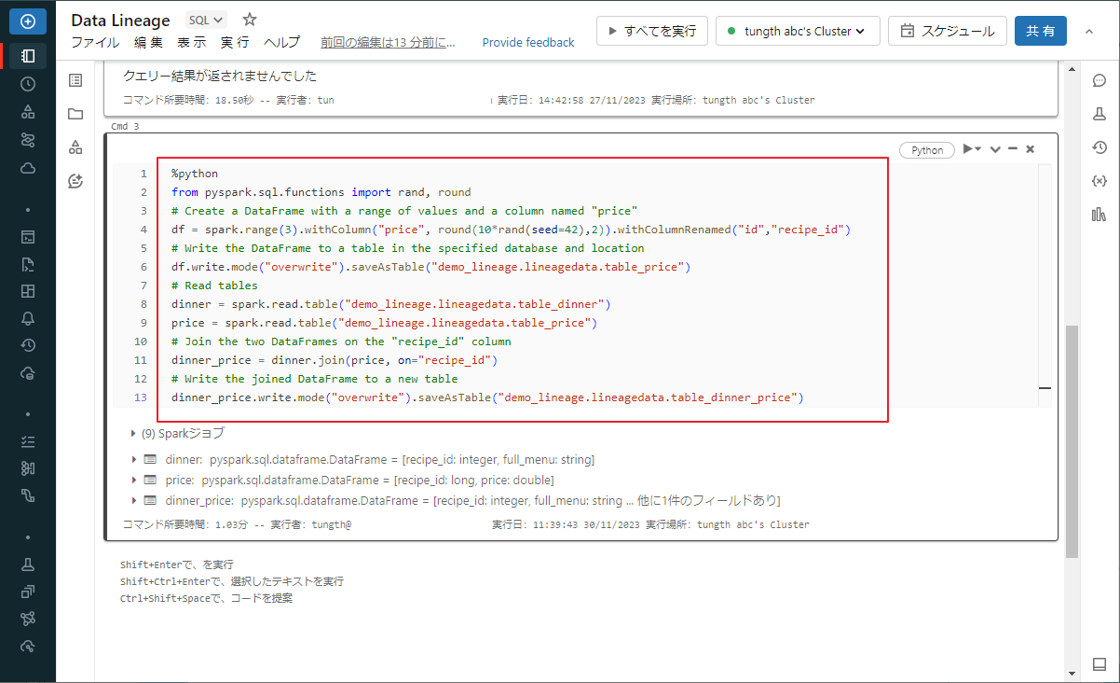
⑦ table_menu テーブルの依存關係タブをクリックし、「リネージグラフを表示」ボタンをクリックして、テーブルの Lineage Graph を表示します。
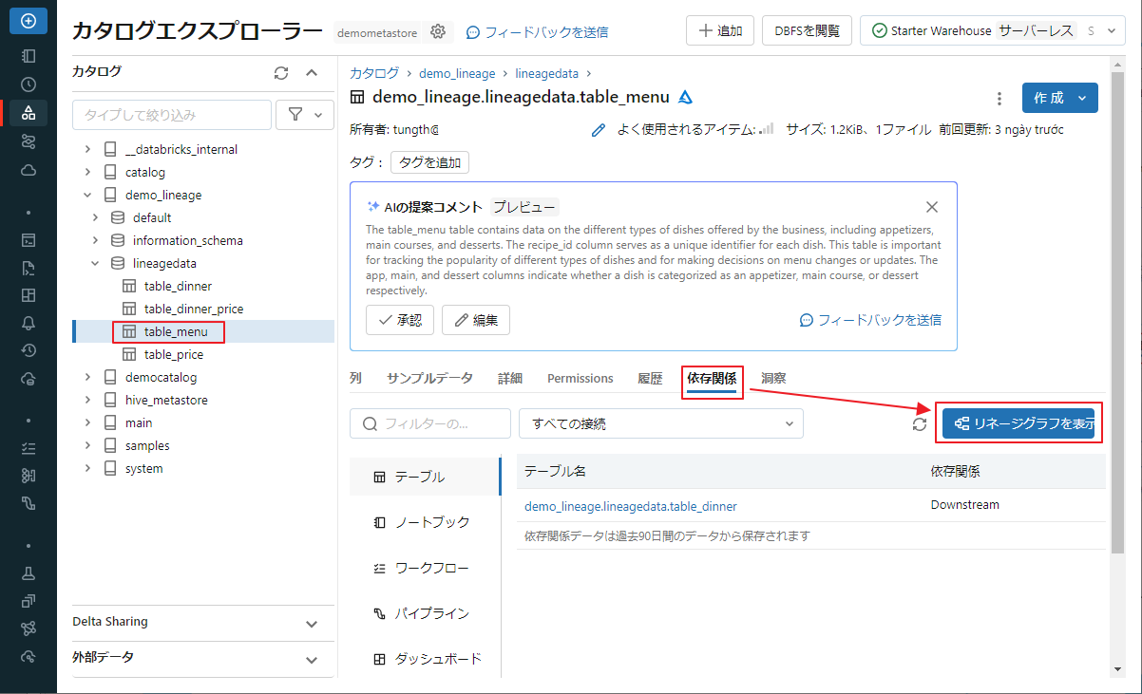
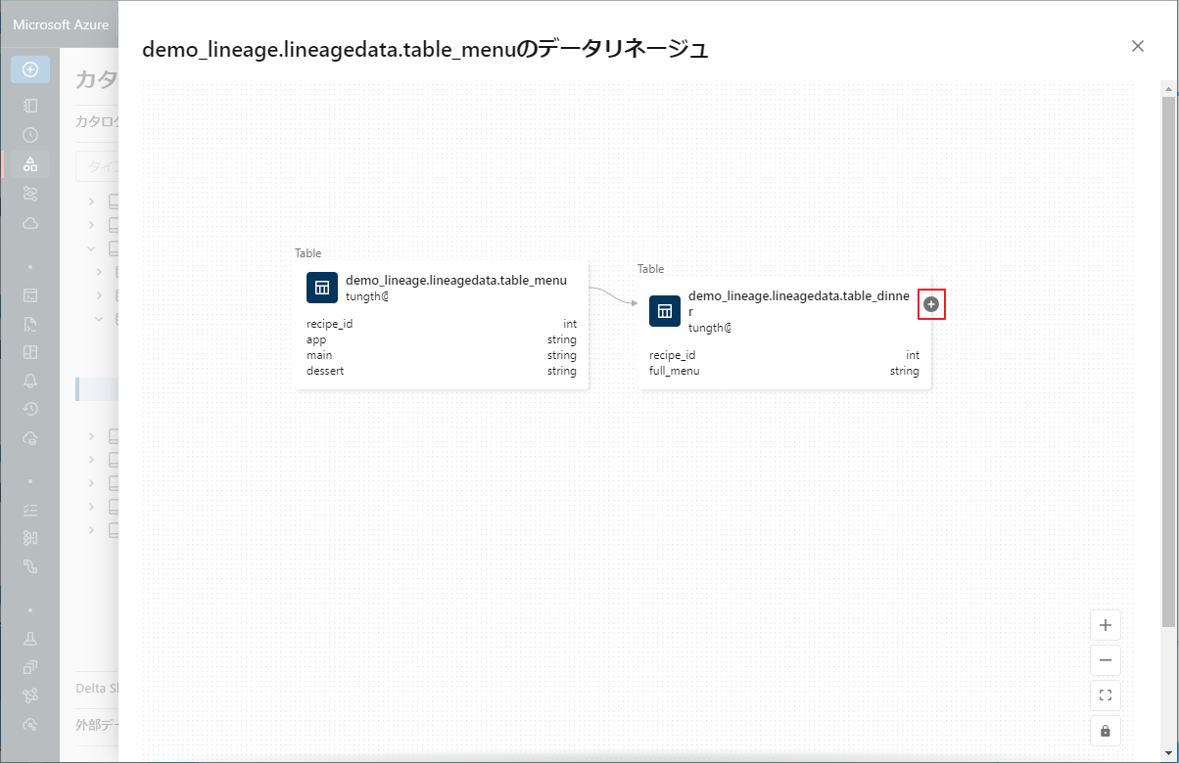
⑧ ![]() アイコンをクリックして、SQL および Python クエリによって生成されたデータリネージを確認します。
アイコンをクリックして、SQL および Python クエリによって生成されたデータリネージを確認します。
リネージグラフを再度見ると、作成した新規テーブルとその接続がわかります。
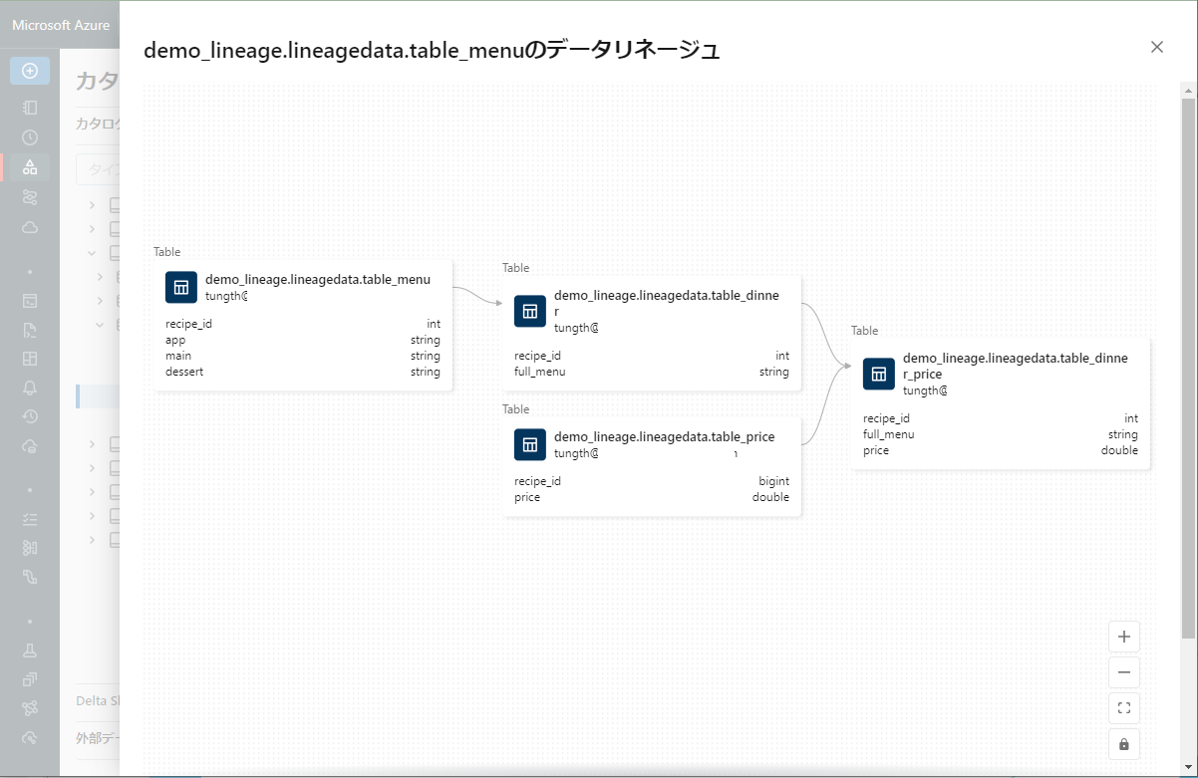
⑨ 各テーブルの各列をクリックすると、テーブル間の接続が列レベルで表示されます。
6.自動化されたリアルタイムのリネージ
自動化されたリアルタイムのリネージとは、クエリが実行されるたびにシステム内のデータの流れを自動的に追跡し、表示する機能です。Unity Catalog は、あらゆる言語(Python、SQL、R、Scala)、実行モード(バッチ、ストリーミング)で実行されたクエリのデータフロー図を自動的に取得し、リアルタイムに表示します。
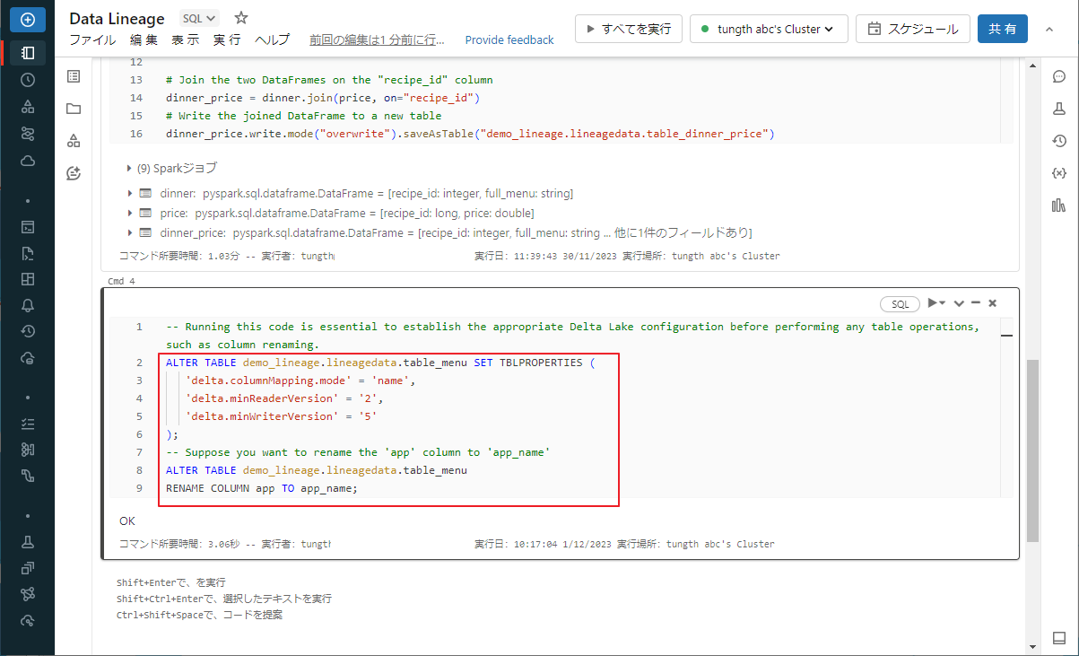
① 前に作成したノートブックを開き、新しいセルを作成し、次の SQL コードを入力します。
table_menu テーブルの列名を「app」→「app_name」に変更します。
|
1 2 3 4 5 6 7 8 9 |
--Running this code is essential to establish the appropriate Delta Lake configuration before performing any table operations, such as column renaming. ALTER TABLE demo_lineage.lineagedata.table_menu SET TBLPROPERTIES ( 'delta.columnMapping.mode' = 'name', 'delta.minReaderVersion' = '2', 'delta.minWriterVersion' = '5' ); --Suppose you want to rename the 'app' column to 'app_name' ALTER TABLE demo_lineage.lineagedata.table_menu RENAME COLUMN app TO app_name; |
②「Shift」+「Enter」キーを押して、コマンドを実行します。
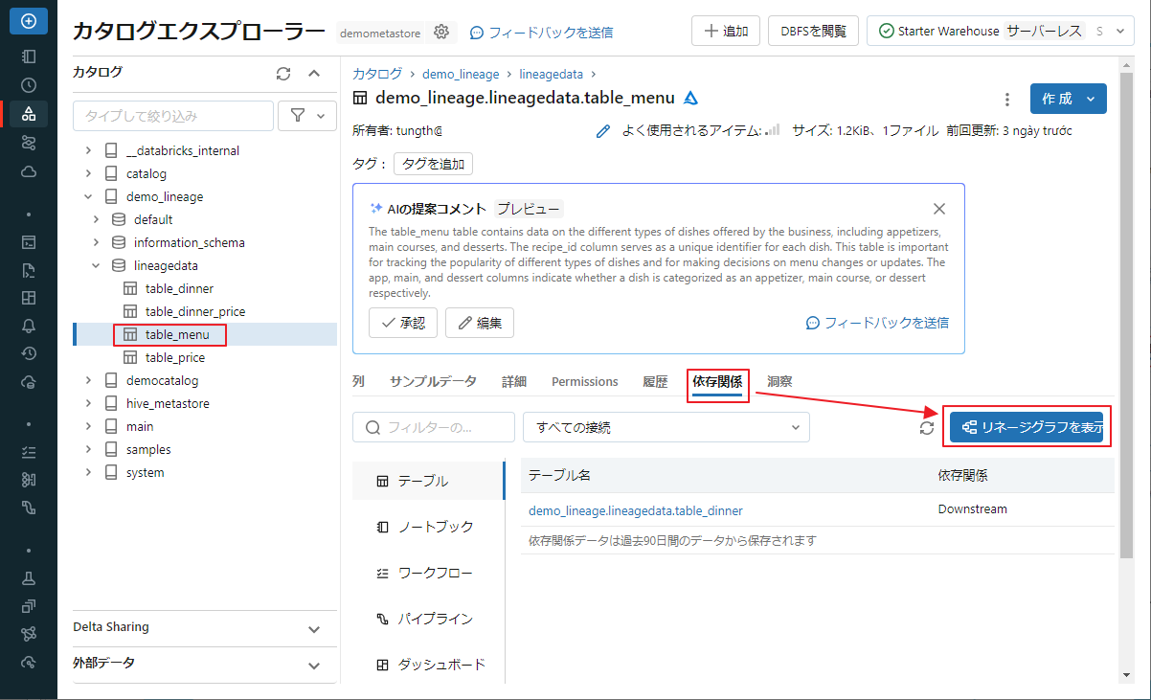
③ table_menu テーブルの依存關係タブをクリックし、「リネージグラフを表示」ボタンをクリックして、テーブルの Lineage Graph を表示します。
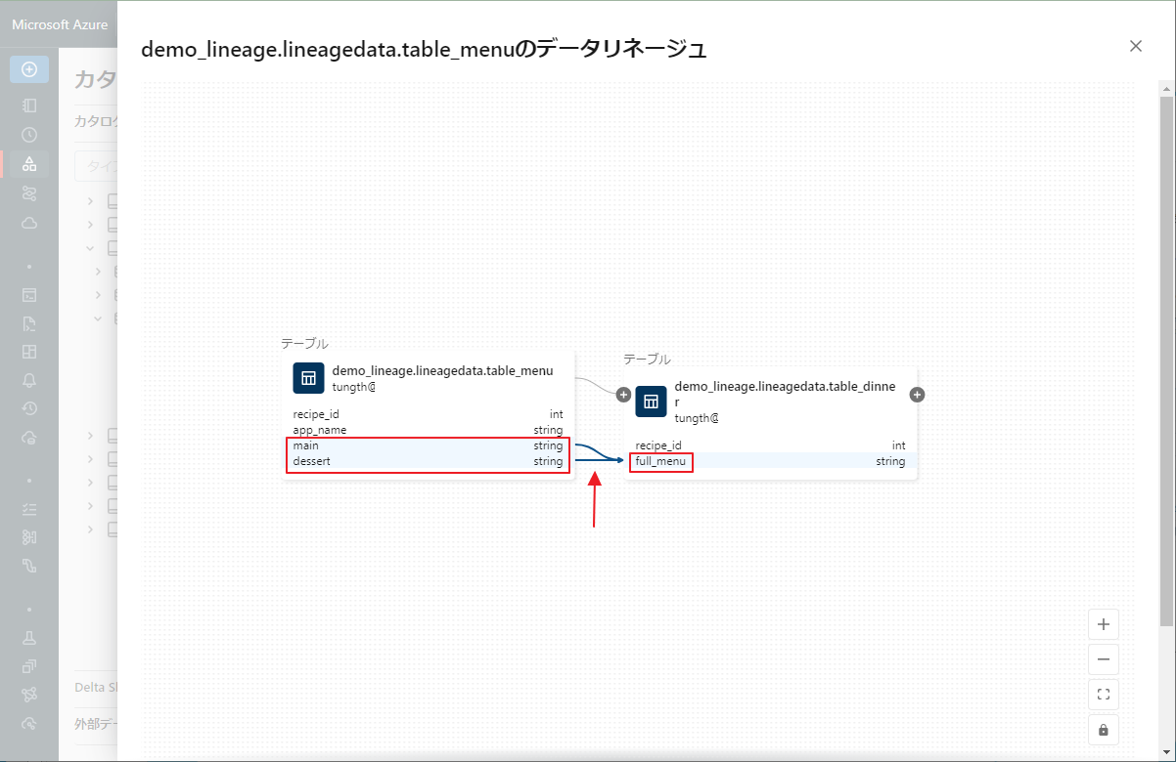
table_menu テーブルの列名を変更した後、table_dinner テーブルの列「full_menu」が、table_menu テーブルの「main」と「dessert」の 2 つ列のみに関連付けられています。
table_dinner が、table_menu テーブルの構造に基づいて作成されるため、table_menu テーブルの変更があれば、ダウンストリーム テーブルに反映されます。
自動化されたリアルタイムのリネージは、変更を自動記録して表示します。これにより、データをどのように構造化し、システム内で移動させるかを正確かつ最新の情報に基づいて把握できます。変更ごとにリネージ情報を手動で更新する必要はありません。
7.まとめ
本連載では、
Azure Databricks データリネージの一般的な使用例と使用方法について説明しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら