データ活用を実現するDatabricksのテクノロジー
Apache SparkとPhoton
高速演算処理でハイパフォーマンス・低コストを実現

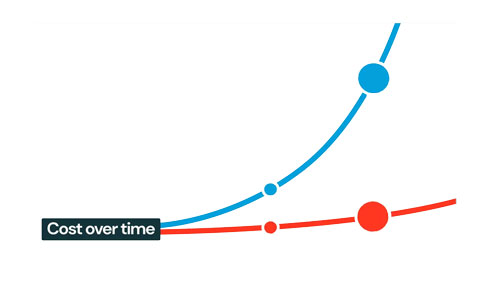
Databricksの費用は、計算処理に必要なコンピューティングリソースの使用時間に応じて課金されます。
Databricksは高速で動作するため、計算処理が短時間で済ませられ、コストを削減することができます。また、データの保存場所として、安価なクラウドサービスのデータレイクのストレージを活用することで、データ保存費用を抑えることが可能です。
また、代表的なクラウドDWHサービスと比較すると、データ量が増加するとコスト差が拡大する傾向があります。
データ基盤の費用が増加すると、データ活用プロジェクトの損益分岐点が上昇するため、コスト重視でDatabricksを採用する企業も増加しています。
Delta Lake
全てのデータにACIDトランザクション保証

Unity Catalog
ユーザーやデータへのアクセスを集中管理
Unity Catalogは、Databricksで提供されるデータガバナンスソリューションです。
Unity Catalogを使用することで、すべてのワークスペースに対して、ユーザーやデータへのアクセスを集中管理することができます。
各ユーザーはUnity Catalogで許可される権限に基づいて、データにアクセスすることができます。また、Unity Catalogはデータのリネージュ機能を提供し、データ加工や統合の変遷を自動的に取得し、データフロー図として可視化します。
これにより、ユーザーは利用するデータについて理解を深め、データ管理者はデータ変更が下流にどのような影響を与えるかを把握することができます。
re dashとML Flow
BIダッシュボードもAI活用も標準提供

Note Book
ブラウザベースでコラボレーション

Databricksでは、ノートブックを利用してデータの処理や分析が簡単に行えます。このノートブックは複数人での共同編集が可能で、効率的なコラボレーションを実現します。さらに、変更履歴を管理する機能も備えています。
サポートされている言語はPython、SQL、Scala、Rと多岐にわたり、ユーザーは任意のライブラリを追加して環境をカスタマイズできます。定期的なタスクの場合、スケジュールされたジョブを設定し、マルチノートブックワークフローを自動で実行することができます。
Databricksが事前に用意したデフォルトのノートブックも用意されており、これを使って自社データを簡単に接続・利用することができます。