Azureではじめるデータレイク
– Azure Data Lakeとは?-
DXを進めるにあたって、データ分析基盤の構築は必須と言えるでしょう。データ分析基盤の構成要素の中でも特に重要なものの1つがデータレイクです。データウェアハウスは知っているがデータレイクは馴染みがない方もまだ多いように見受けられます。またデータレイクは知っているが、どこにどのようにして構築するのがよいかわからないという方もいるでしょう。そこで本記事ではそのような方々のために、データレイクの概要と、クラウド上のデータレイク提供サービスであるAzure Data Lakeについてご紹介します。
Azure Data Lakeの詳細情報はこちら >
本ブログはこんな方にオススメです
- データレイクの導入を考えている
- クラウドMicrosoft Azureでデータレイクを導入する方法を知りたい
- Azure Data Lakeの特徴を知りたい
目次
1. そもそもデータレイクとは?
データレイクとは規模や形式にかかわらず全てのデータを一元的に保存できる格納庫のことです。データの形式は、RDBやCSVファイルのような規則性のある構造化データと、文書・画像・動画・音声など不規則な形式の非構造化データに大別できますが、あらゆるデータを生データ(Raw Data)のまま保管できることがデータレイクの最大の特徴です。
データ分析基盤を構築する際に、データレイクと並んで重要なものがデータウェアハウス(DWH)です。DWHに関しては馴染みがある方も多いと思われますので、これと比較するとイメージが掴みやすいかもしれません。
| データレイク | データウェアハウス | |
| データ構造 | ローデータ | 構造化データ(RDBが多い) |
| 利用目的 | 特定の目的を持たない | データ分析に最適 |
| ユーザー | データサイエンティスト
※最近ではビジネス担当者も |
ビジネス担当者 |
| アクセス性 | 柔軟にアクセス可能 | 安全性と検索性が高い |
| 変更容易性 | 迅速に更新できる | 正規化されているため更新コストがかかる |
DWHは正規化(データの重複などない状態)された構造化データを格納していますので、検索や分析を高速に行うことができますが、データの加工に時間とコストがかかるためデータの収集や蓄積には不向きです。
一方データレイクはデータの形式に関係なく、生データをそのまま格納していくため、今後どのように使われるかわからないデータでもとりあえず収集し、蓄積しておくことができます。将来が予測しにくい現在のビジネス環境では、どのようなデータが有効になるか発生時点に見極めるのは難しいことから、データレイクのような格納庫を、柔軟に縮小・拡張ができるクラウド上で導入することが求められるようになりました。
下記では、MicrosoftのクラウドAzureにて導入できるAzure Data Lakeについて解説します。
2. Azure Data Lakeとは?
Azure Data Lake は、Microsoft Azure(クラウド)から提供されるデータレイクのサービスです。PaaSといわれる領域のサービスとなります。さまざまなサイズ、形状、スピードのデータを容易に格納し、複数のプラットフォームと言語であらゆる種類の処理と分析を簡単に実行するために必要な機能がすべて組み込まれているのが特長です。Azure Data Lakeには大きく3つの機能が備わっています。1つはデータを格納する領域の「Azure Data Lake Store」、2つ目は格納したデータを分析するための「Azure Data Lake Analytics」、3つ目はデータを管理するための「Azure HDInsight」です。これらの機能によりさまざまな種類のデータを格納し、複数のプラットフォームと言語で処理/分析を簡単に実行できるようになります。複雑性は排除されているのでデータを保存/分析する方法に悩むことなく、大規模なデータセットの処理やペタバイト規模のファイルと数十億個のオブジェクトを保管/分析することが可能です。
機能① Azure Data Lake Storage(ストレージ)
データレイクを構築するためのストレージサービスです。
1 ペタバイトを超えるファイルを数十億個も保存することができます。使用するストレージのスペックを増やしたり減らしたりする際のコードの書き直しなども不要なので、ビッグデータを管理する際の煩雑さはありません。
Azure Active Directory(Azure AD)とRBAC(ロールベース・アクセス制御)でデータを認証します。また暗号化や脅威に対する高度な対策などのセキュリティ機能でデータを保護します。
元々はHadoopをベースとしたAzure Data Lake Storage Gen1と呼ばれるサービスでしたが、こちらは2024年2月29日に廃止となります。そこで現在ではGen2の導入をお勧めしています。
※Azure Data Lake Storage Gen2は、Gen1とAzure Blob Storageの機能を集約したものです。Azure Blob Storage は、Microsoft のクラウド用オブジェクト・ストレージ・ソリューションです。この機能集約により、Gen1よりさらに低コストで提供できるようになりながら、高可用性、一貫性、ディザスタリカバリー性が高まりました。
機能② Azure Data Lake Analytics(分析ツール)
SaaS型のオンデマンド分析ジョブサービスです。SQLと似たU-SQLを使用して、大容量データを数秒で処理することができます。ジョブごとにAzure Data Lake Analyticsユニット(AU)という処理能力を割り当てることで、パフォーマンスを調節することができます。
リソースが動的に割り当てられるため、テラバイトからエクサバイト規模のデータも分析できます。課金は実行時間とAUの掛け算となります。
機能③ Azure HDInsight(管理)
オープンソースの技術を活用したクラウド上の大規模分析サービスです。Azure Data Lake AnalyticsがU-SQLでのデータ処理であるのに対して、Azure HDInsightでは、Azure 環境でHadoop、Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Storm、Rなどのオープンソース・フレームワークを利用できます。
定評のある他のビッグデータ解析アプリケーションとシームレスに連携できるなど、機能拡張の容易さも大きな特長です。
\各機能について知りたい方は資料もご参照ください/
![]() Azure Data Lakeの
Azure Data Lakeの
概要資料をダウンロードする
3. Azure Data Lakeにデータを取り込む方法
Azure Data Lakeにデータを取り込む際には、Azure Data FactoryまたはAzure Event Hubsと連携します。以下にその概要を説明します。
① Azure Data Factoryを使用してAzure Data Lake Storageにデータを読み込む
Azure Data Factoryは、ノーコードでデータ連携プロセスを簡単に構築できるクラウド上のELT/ETLツールです。その目的からAzure内外の様々なサービスとの連携が可能となっています(図)。データ連携の結果統合されたデータをAzure Data Lake Storageに読み込ませることも可能です。
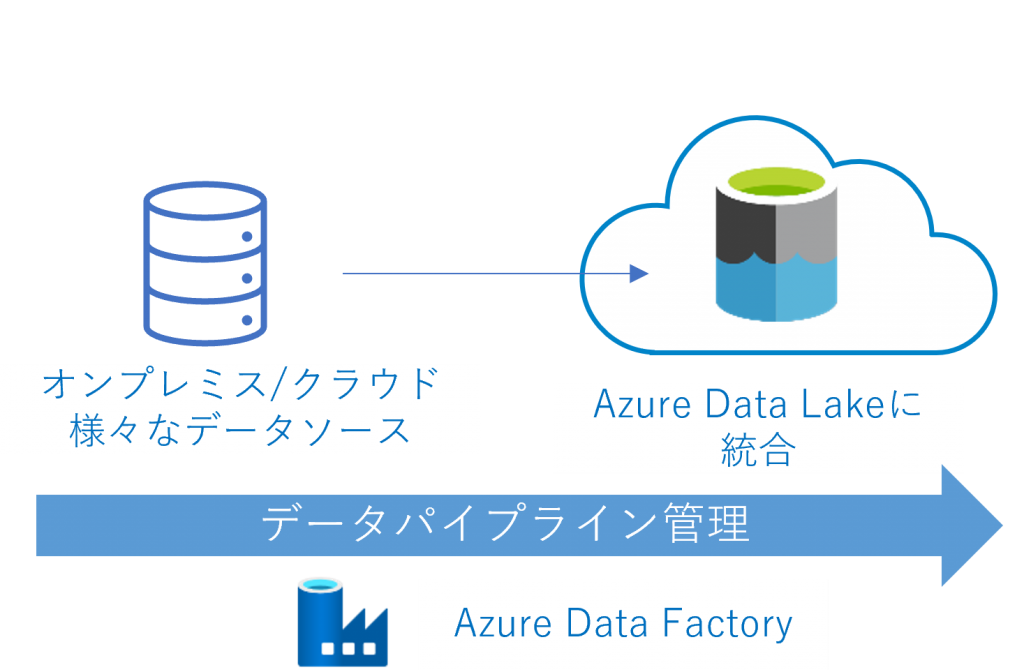
具体的な手順は以下の通りです。
① Azure Marketplaceのメニューから「Data Factory」を選択し、必要な値を設定して、新しいデータ ファクトリを作成する
② 「データ ファクトリ」ホームページが開くので、そこからデータのコピーツールを起動して、タスクの種類やスケジュールを設定する
③ 画面からデータソースを指定し、ID等を指定して接続する
④ コピーするフォルダとファイルを選択し、コピーの動作やオプションを指定する
⑤ Data Lake Storage Gen2対応のアカウントを選択して接続する
⑥ 新しく作成した接続を選択して、出力先フォルダを選択する
⑦ 既定の設定を使用して、パイプラインを実行する
② Azure Event HubsでAzure Data Lakeにイベントをキャプチャする
ファイルとして存在する静的なデータをバッチ処理的に統合する際にはAzure Data Factoryを使用しますが、無制限に発生する大量データ(ストリーミングデータ)をリアルタイムに処理する際にはAzure Event Hubsを使用します。
Azure Event Hubsを利用するとストリーミングデータを、選択したAzure Blob Storage アカウントまたは Azure Data Lake Storageアカウントに自動的に配信できます。
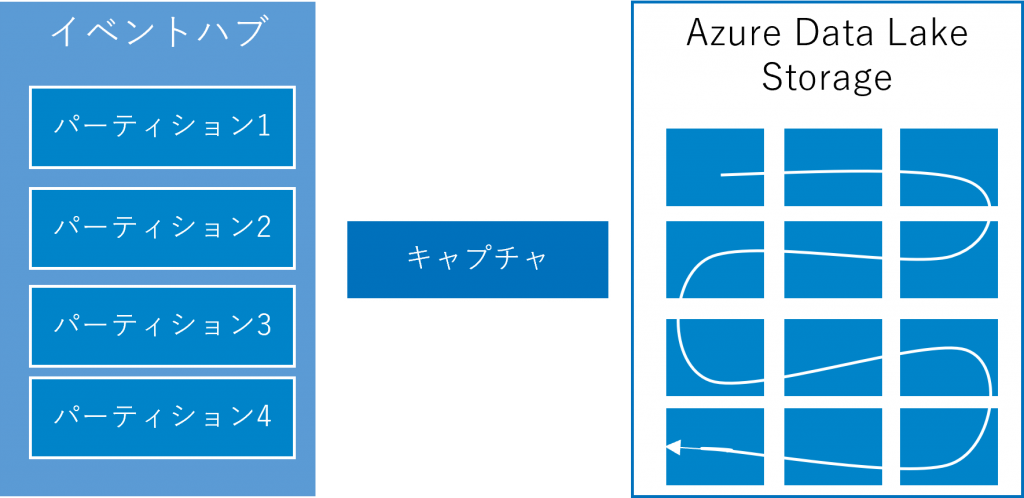
時間やサイズの間隔を柔軟に指定でき、リソースが自動的にスケーリングされるので管理コストが発生しません。Event Hubsによるキャプチャはストリーミングデータを読み込む最も簡単な方法で、ユーザーは煩わしい設定や管理から解放されて、データの処理に注力できます。
![]() Azure Data Lakeの
Azure Data Lakeの
概要資料をダウンロードする
4. Azure ADとの統合でセキュリティを強化できる
データ分析のためのセキュリティには、5つの管理原則があります。
5つの管理原則とは
① 権限を持っている単一のソースを一貫して使用することで、明確性を高め、人的エラーおよびデータ構成や処理の複雑さによるリスクを軽減する
② 自動化、監査、複数の管理ポイントの実装により人的エラーを軽減し、データガバナンスを容易にする
③ ユーザーがジョブを実行するのに必要なアクセス件のみを付与し、アクセスできるスコープと許可されるアクションを制限する
④ 複雑さにつながることでリスクを増やすことになるため、カスタマイズを禁止する
⑤ ルールおよび定義を明確にし、ルールを守りやすくする
共通する考え方は、できるだけ様々な要素を単純化することと、人間による操作を減らすことでセキュリティリスクを低減することです。この原則によれば、データレイクソリューションのID管理や認証は、既に使用されているディレクトリサービスに統合する必要があることがわかります。
Azure上の多くのサービスにおけるID管理・認証は、Azure ADに統合することができます。Azure Data Lakeもその1つです。
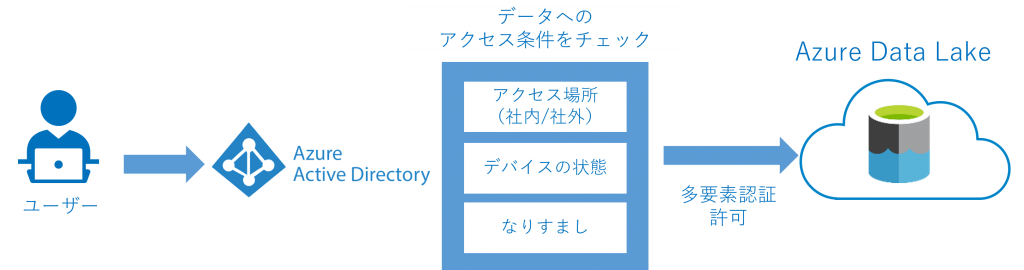
データ レイクへのアクセスを制御するには、ファイルおよびフォルダのレベルでアクセス制御リスト(ACL)を作成することが推奨されています。その際にACLには次のルールを適用する必要があります。
- Azure ADグループへのアクセスを割り当て、グループのメンバーシップを管理する
- できる限りデータレイク内の必要なフォルダおよびファイルへの読み取りアクセス許可のみに限定する(特にストレージ・アカウント・コンテナーにはアクセスできないようにする)
- ACLとデータ・パーティションの設計を合わせる
5. Azure Data Lakeの料金体系
Azure Data Lake Storage、Azure Data Lake AnalyticsおよびAzure HDInsightの料金体系は、それぞれの使い方に応じた柔軟な従量課金になっています。それぞれの詳細については、下記のリンク先を参照してください。リージョンと通貨を選択することで料金表がカスタマイズされます(HDInsightについては、時間単位として月または時間を指定できます)。
Azure Data Lake Storage
データ容量に応じた月額従量課金
https://azure.microsoft.com/ja-jp/pricing/details/storage/data-lake/
Azure Data Lake Analytics
ジョブ単位による従量課金
https://azure.microsoft.com/ja-jp/pricing/details/data-lake-analytics/
Azure HDInsight
必要なインスタンスとコンポーネントの組み合わせによる従量課金
https://azure.microsoft.com/ja-jp/pricing/details/hdinsight/
まとめ
データレイクは、規模や形式にかかわらず全てのデータを一元的に保存できる格納庫です。構造化データ、非構造化データにかかわらず、様々なデータを統合して、大量に保存して、そこからデータを集約・加工したり、大規模なデータセットに対して分析クエリを実行したりしたい場合に向くものです。一方で頻繁な読み書きや、多数の細かいデータの参照などには向いていません。
Azure Data Lakeは、Azure Data Lake Storage、Azure Data Lake AnalyticsおよびAzure HDInsightの3つのコンポーネントからなり、Azure Data FactoryやAzure Event Hubsと連携することで、クラウド上に簡単にデータレイクを構築し、分析することを可能にするサービスです。料金体系は、柔軟な従量課金制になっています。
Azureサービスを活用してデータ分析に取り組んでみたい方は、以下の資料もぜひ参考にしてください。
Azure Data Lake概要資料のダウンロード
Azure上データレイクを構築したい方、
Azure Data Lakeの全体像を知りたい方は、是非ご覧ください。
この記事を書いた人

-
こんにちは!日商エレクトロニクスでは、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~
- 2024年2月19日ブログMicrosoft Azure とは?基本概要、5大メリット、主要サービスを解説
- 2024年2月6日ブログ今さら聞けない「DWH」とは? ~データベースやデータマートとの比較も含めて解説!~