データ活用に必要な5つの要素とは?
課題と実現方法を解説

DXの進展に伴い、多くの企業でもデータ分析から得られた知見をビジネスに活用し、活用した結果で得られたデータをまた分析するというサイクルを回すことが一般化してきました。このサイクルはPDCAを繰り返しながら高速に回すことが求められることから、データ分析をベンダーに頼らず自社で、さらにIT部門ではなく現場部門で実施するという「内製化」の動きが顕著になっています。とは言うもののそのための環境もツールなく、いきなりデータサイエンスやITの専門家でない社員に「データを活用せよ」と言うのは難しいですよね。
そこで本ブログでは、社内におけるデータ分析を内製化するためにまずは押さえておきたい基本要素5つ、課題と解決策を紹介していきます。
本ブログはこんな方にオススメです
- 社内におけるデータ分析を内製化したい
- クラウドのメリットを活かしてデータ活用を促進していきたい
※なお本ブログは2021年12月16日開催「Azureではじめるデータ活用」セミナーより、日本マイクロソフト 樋口拓人氏登壇「今、すべての企業に求められるクラウドデータ利活用」の内容を抜粋したものです。
▼Azureではじめるデータ活用~セキュリティを担保したデータ基盤を作る方法~(セミナー動画はこちら)
https://contacts.nissho-ele.co.jp/azure_data_platform_ondemand.html
目次
1.データ活用に必要な5つの要素
まずデータ活用に必要な5つの要素を説明します。

① データ基盤のクラウド化
データ分析・活用を進めるためには、社内外あらゆる場所に存在しているデータを統合する必要があります。その際に重要になるのがデータ基盤の「拡張性」です。
クラウド環境、もしくはオンプレミスとクラウドのハイブリッド環境上にデータ基盤を用意することで、あらゆるデータの統合をスムーズに実行できるようになります。
② クラウドに対応するアプリケーション
データはあくまでも手段であり、データ活用のためには分析結果を反映するアプリケーションが重要です。ユーザー数の増減に容易に対応できるクラウドネイティブなアーキテクチャとそれに柔軟に対応できるデータベースが必要です。
③ 分析とインサイト
リアルタイムに分析結果(顧客や市場の動向など)を把握し、得られた知見から価値を生む分析を実行するための基盤が必要です。
④ データサイエンス
AI、機械学習を高度な専門スキルなしでもすぐに適用できる基盤が必要です。
⑤ データガバナンス
どの部門にどんなデータがあり、それを誰がどうやって作成したか、個人情報に該当するのがどれかなどを全般的・一元的に管理し、必要なデータをすぐに探し出せる仕組みが必要です。
2.企業におけるデータ活用パターンと課題
上記にて社内におけるデータ活用に必要な5つの要素をご紹介しました。では、それらを実現するためにはどうしたらよいのでしょうか。
その前に現在、企業における代表的なデータ活用のパターンとして大きく2つあるのですが、それぞれの特徴と課題について解説します。
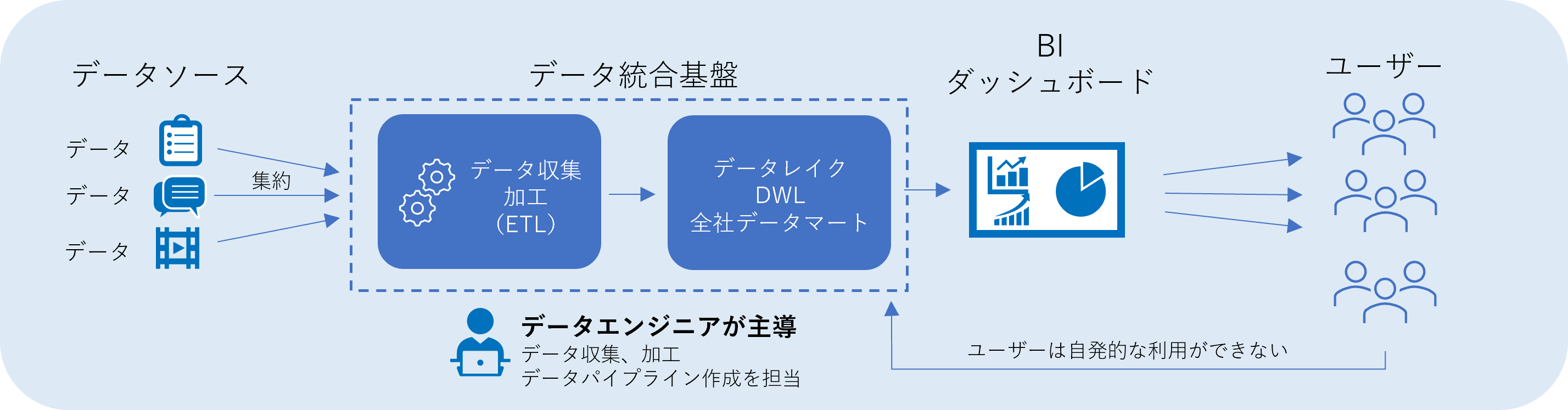
①エンタープライズ(IT主導)型
エンタープライズ型は、企業内のIT部門の方々が中心となって推進します。データ基盤を運用している専門知識を持った部隊が、経営層向けやや全社レベルのKPIをモニタリングしたレポートなどを作成し、そのためのデータ収集、ETLパイプラインなどを開発します。この場合、経営層や社員向けに統一されたレポートが提供される反面、以下の課題もあります。
課題
・IT部門は依頼ベースで機能追加するうえ、一極集中するためリクエスト迅速性に欠ける
・ユーザーは生データを自発的に活用する方法が分からず、データ活用が進みにくい
▼エンタープライズ(IT主導)型のイメージ
②セルフサービス(現場主導)型
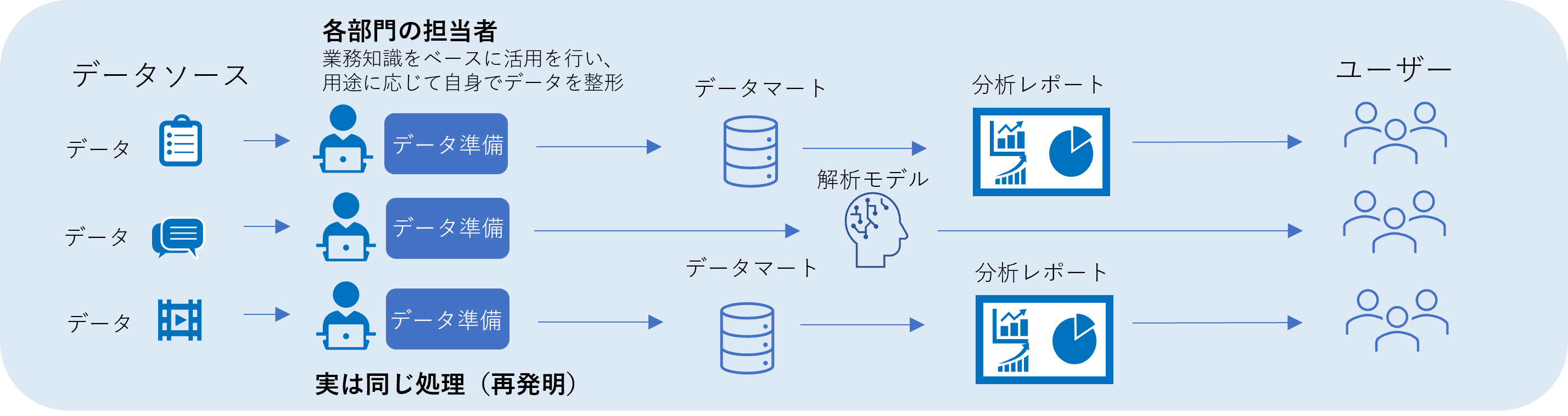
もう1つのセルフサービス型は、現場部門が自らデータを分析・活用を進める方式で、迅速にアウトプットが得られるため、近年注目されている方式です。多岐にわたるビジネスニーズに対応できるため、部門内でのデータ活用を促進することができます。
課題
・異なる部門で同じような処理をする「再発明」が頻発
・同じデータでも処理が違うため異なる結果が得られて一貫性に欠ける
・現場の自由に任せるほど、データやツールのサイロ化が顕著になる
▼セルフサービス(現場主導)型のイメージ
③双方の課題を解決するハイブリッド型
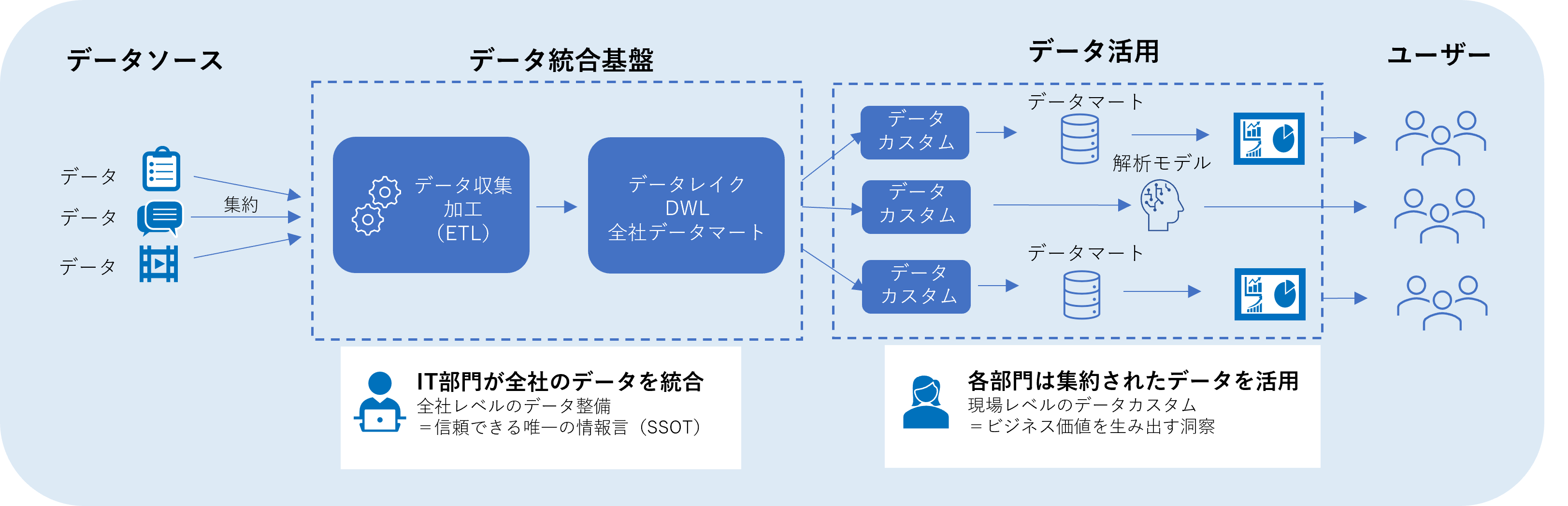
最近では、双方のメリットを掛け合わせて上記の課題を解決できるハイブリッド型で進めようという動きが近年活発になっています。
ハイブリッド型でのIT部門の役割は、全社レベルでデータを整備・統合して、信頼できる唯一の情報源(SSOT、Single Source Of Truth)を用意することです。そしてその整備された基盤を活用して現場部門は、集約されたデータを必要なときに、必要なデータだけを加工し、分析や機械学習で活用することができます。
▼ハイブリッド型のイメージ
3.ハイブリッド型でデータ活用するために重要なデータガバナンス
ハイブリッド型で運用するに当たって、特に重要になるのがデータガバナンスです。データを統合して、SSOTを実現すること自体もデータガバナンスの一部ですが、それだけでは十分ではありません。データは使われてこそ価値を生むので、ユーザーが必要とするデータをただちに探し出せなければ意味がないのです。
意味のあるデータガバナンスを実現するためには、データガバナンスに最適なデータ管理手法「メダリオン・アーキテクチャ」を知っておくとよいでしょう。
メダリオン・アーキテクチャーとは?
メダリオン・アーキテクチャーとは、従来生データ(raw data)と加工済みデータの2層で捉えていたデータ管理を、Bronze・Silver・Goldの3層で捉え直して管理する手法です。Bronzeは生データ、Silverはクレンジング済みのデータ、Goldはそのまま分析に使えるデータマート的なデータに該当します。
ユーザーは、普段はGoldを使用してデータから知見を得ますが、新たな知見を得たい場合にはSilverに遡ってそこからGoldを作成することができます。それでも不足の場合には、IT部門にリクエストして、BronzeからSilverを作成してもらいます。
データを鮮明度に従って3階層に分けて、役割や責任を明確に分担することでデータガバナンスに好影響を与えることができるわけです。

メダリオン・アーキテクチャーの特徴
- 生データと加工済みという従来の2層データの概念を拡張しBronze、Silver、Goldの3層で解釈
- ステージ毎のデータの役割明確化によるガバナンスへの好影響
データ消費者にとってのメリット
- 利用者に必要なデータがステージとして整理されている=責任、関心の分離
- ステージを遡れば、新たな知見を得るための元情報にアクセスできる
4.データ活用に必要な5つの要素の実現方法
1の章でご紹介したデータ活用に必要な5つの要素、さらにメダリオン・アーキテクチャの考え方を基にした場合、Microsoft Azureのサービスを活用することでデータ加工・分析の内製化の枠組みを導き出すことができます。
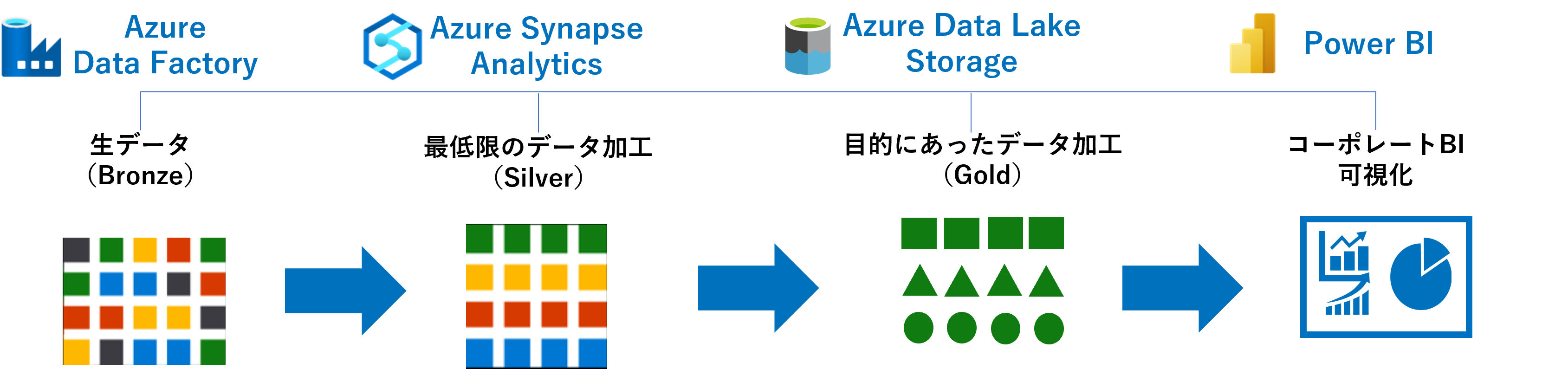
具体的には、BronzeをSilverに変換するにあたってはAzure Data Factory、SilverからGoldへはAzure Synapse Analytics、さらにGoldを格納するにはAzure Data Lake Storageを利用することになります。またユーザーがデータを探し出せるようにするためには、Bronzeを加工する段階からAzure Purviewを使って、このデータは誰がどうやって作成したかをデータカタログに登録します。さらにPower BIやAzure Machine Learningを使うことで、データサイエンスやITの専門家でなくても容易にGoldを活用することができます。
これらのデータベースやプラットフォームは、Common Data Modelという標準化された構造(スキーマ)で利用することができます。標準化されているため、システム開発や学習が容易となり、生産性が向上します。
5.データ活用の内製化に成功した企業の取り組み
Azureを活用することで、データ活用の内製化に成功した企業の事例を紹介します。
① 某運送会社
この会社では、従来IaaSで構築していたデータ分析基盤をPaaSのビッグデータ分析基盤であるAzure Synapse Analyticsに移行しました。このことによりIT部門の運用管理負荷が大幅に軽減し、データメンテナンスが以前よりも容易になりました。
また現場部門では、機械学習で作成した予測モデルを現場の担当者が参考にして、配送センターの人員配置を決定するなどのデータ活用が実現されています。
② 某インテリア会社
この会社では、ECサイト、実店舗、社内アプリケーションに散在していたデータをAzure Data Factoryで集約し、社内の顧客情報の一元管理を実現しました。
その結果、現場部門ではAzure Machine Learningを使用してノーコードで機械学習を実行し、優良顧客の判定や購買特徴のマイニングを簡単かつ迅速に行えるようになったのです。
もともと社内データサイエンティストが在籍していないのですが、マイクロソフトの内製化支援プログラムを活用することでAIモデル作成の内製化をほぼ達成することができました。
③ 某製薬会社
この会社では1TBを超えるリアルワールドデータ(実際の臨床の中で得られる医療データの総称)を保持しています。これらを分析するためには、オンプレミス上に開発した分析基盤ではパフォーマンス不足でした。性能改善しようにもブラックボックス化が進み、現実的でなくなっていたのです。
そこで既存の分析基盤を構築したSIerとしっかりと協業しつつも、最終的には自社で分析基盤を構築・運用する決断をしたのでした。
同社が分析基盤に採用したのは、データ分散処理プラットフォームであるAzure Databricksでした。オートスケールとオートターミネートでリソースを柔軟にスケールできることが採用の決め手だったと言います。
6.まとめ
データ利活用には、①データ基盤のクラウド化、②クラウドネイティブ・アプリケーション、③分析とインサイト、④データサイエンス、⑤データガバナンスの5つの要素が不可欠です。
これらの要素をすべて用意するための理想的なデータ活用型が、IT部門と現場部門の役割分担と責任範囲を明確に分離したハイブリッド型であり、近年その方式でのデータ基盤整備が活発化しています。
ハイブリッド型のデータ基盤を実現するためにはデータガバナンスが欠かせません。データガバナンスを実現するための考え方が、Bronze・Silver・Goldの3層で管理するメダリオンアーキテクチャです。
Azureにはメダリオンアーキテクチャを実現するための製品がすべて揃っており、内製化を実現するための有力な選択肢だと言うことができます。
\データ活用プロジェクトのはじめ方/
データ活用プロジェクトをどう進めたらいいか知りたい!
データ活用に成功している企業の事例が知りたい!
という方向けに、プロジェクトの進め方のヒントをお届けします。

この記事を書いた人

-
こんにちは!日商エレクトロニクスでは、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~
- 2024年2月19日ブログMicrosoft Azure とは?基本概要、5大メリット、主要サービスを解説
- 2024年2月6日ブログ今さら聞けない「DWH」とは? ~データベースやデータマートとの比較も含めて解説!~